Hosting pro vysoce zátěžové aplikace: Jak škálovat web pro miliony uživatelů




Provoz webu pro miliony uživatelů dnes není otázkou jednoho silného serveru, ale správně navržené architektury, automatického škálování a práce s výkonem na všech úrovních (od infrastruktury až po databázi). Podíváme se, jaké principy a technologie skutečně rozhodují o tom, zda aplikace zvládne extrémní zátěž bez výpadků a zbytečných nákladů.
Co znamená škálovatelnost
Škálovatelnost v kontextu webů a aplikací znamená schopnost systému dlouhodobě zvládat rostoucí zátěž (více uživatelů, požadavků a dat) bez zásadního zhoršení odezvy, stability nebo dostupnosti služby. Nejde tedy jen o to, že se web ještě nerozpadne, ale že si i při násobně vyšším provozu zachová předvídatelné chování.

Důležité je, že škálovatelnost není vlastnost jednoho serveru, ale celé architektury. Skutečně škálovatelný systém je navržen tak, aby bylo možné průběžně přidávat výkon tam, kde se objevuje úzké hrdlo (typicky ve výpočetní vrstvě, databázi nebo síťové infrastruktuře) bez nutnosti zásadního přepisování aplikace.
V praxi se pod pojmem škálovatelnost skrývají dva základní přístupy:
- Vertikální škálování – navyšování výkonu jednoho stroje (více CPU, paměti, rychlejší disk).
- Horizontální škálování – přidávání dalších instancí aplikace a rozdělování zátěže mezi ně.
Pro vysoce zatěžované aplikace je klíčový především druhý přístup. Horizontální škálování totiž umožňuje reagovat na růst provozu postupně a eliminuje závislost na jednom konkrétním serveru.
Klíčové architektonické komponenty
1) Load balancing – rovnoměrné rozdělení zatížení
Load balancing zajišťuje, aby se příchozí požadavky rovnoměrně rozdělovaly mezi více aplikačních instancí. Uživatel komunikuje s jednou adresou, ale samotné zpracování probíhá na více serverech. Díky tomu aplikace zvládne vyšší zátěž a zůstává dostupná i při výpadku části infrastruktury.
V praxi řeší tři klíčové věci:
- vyšší výkon – zátěž se rozloží mezi více instancí,
- vyšší dostupnost – nefunkční server je automaticky vyřazen,
- snadné škálování – nové instance lze přidávat za běhu.
Nejčastěji se používají nástroje jako HAProxy nebo NGINX, případně spravované služby typu AWS Elastic Load Balancing.
Pro vysoce zatěžované aplikace je load balancer klíčový hlavně proto, že umožňuje horizontální škálování aplikační vrstvy bez zásahů do samotné aplikace.
2) Cloud hosting a auto-scaling – elastická kapacita
Cloud hosting staví infrastrukturu na principu elastické kapacity. Výkon není pevně daný jedním serverem, ale může se průběžně měnit podle aktuální zátěže aplikace.
Klíčovou roli zde hraje auto-scaling. Ten automaticky:
- přidává nové aplikační instance při nárůstu provozu,
- odebírá je ve chvíli, kdy zátěž klesá,
- reaguje na metriky jako vytížení CPU, počet požadavků, latence nebo délka front.
Výsledkem je, že aplikace zvládá špičky (kampaně, mediální zásahy, sezónní provoz) bez ručních zásahů administrátora a zároveň zbytečně neplatí za nevyužitý výkon.
V praxi to znamená, že aplikační vrstva běží ve více instancích, které jsou řízené škálovací politikou a typicky stojí za load balancerem. Pokud některá instance selže, platforma ji automaticky nahradí novou.
Tento model je dnes standardem u platforem jako Amazon Web Services, Google Cloud nebo Microsoft Azure.
Pro vysoce zátěžové aplikace je zásadní, že auto-scaling umožňuje škálovat výkon plynule a bez výpadků, oddělit růst aplikace od konkrétního serveru, zvládat i velmi krátké, ale extrémní špičky v provozu.
3) Databázové škálování
U vysoce zatěžovaných aplikací bývá databázová vrstva velmi často největším omezením výkonu celého systému. Zatímco aplikační servery lze poměrně snadno přidávat, databázová vrstva vyžaduje pečlivější architekturu (zejména kvůli konzistenci dat).
Základním krokem je replikace databáze. Zápisy jdou na hlavní instanci, zatímco čtecí dotazy se obsluhují z jedné nebo více replik. Tím se výrazně sníží zátěž a systém zvládne násobně více uživatelů, kteří data převážně čtou.

Jakmile už nestačí ani tento model, přichází na řadu sharding – horizontální dělení dat. Data se rozdělí do více databází podle klíče (např. uživatel, region, tenant) a každá databáze obsluhuje jen část datasetu.
Výhodou je prakticky neomezená možnost dalšího růstu, nevýhodou vyšší složitost aplikace a dotazování.
Vedle samotného výkonu je velmi důležitá také dostupnost databáze. Běžnou součástí architektury proto bývá:
- automatický failover při výpadku hlavní instance,
- synchronní nebo asynchronní replikace,
- oddělení provozu aplikací od konkrétní databázové instance.
Pro aplikace s miliony uživatelů platí jednoduché pravidlo. Pokud není databázová vrstva od začátku navržena pro replikaci a dělení zátěže, stane se dříve nebo později limitem celého růstu.
4) Caching – zrychlení odezvy
Caching patří k nejúčinnějším způsobům, jak zvýšit výkon a stabilitu vysoce zatěžovaných aplikací. Princip je jednoduchý, často používaná data se nečtou opakovaně z databáze, ale vracejí se z rychlé paměťové vrstvy.
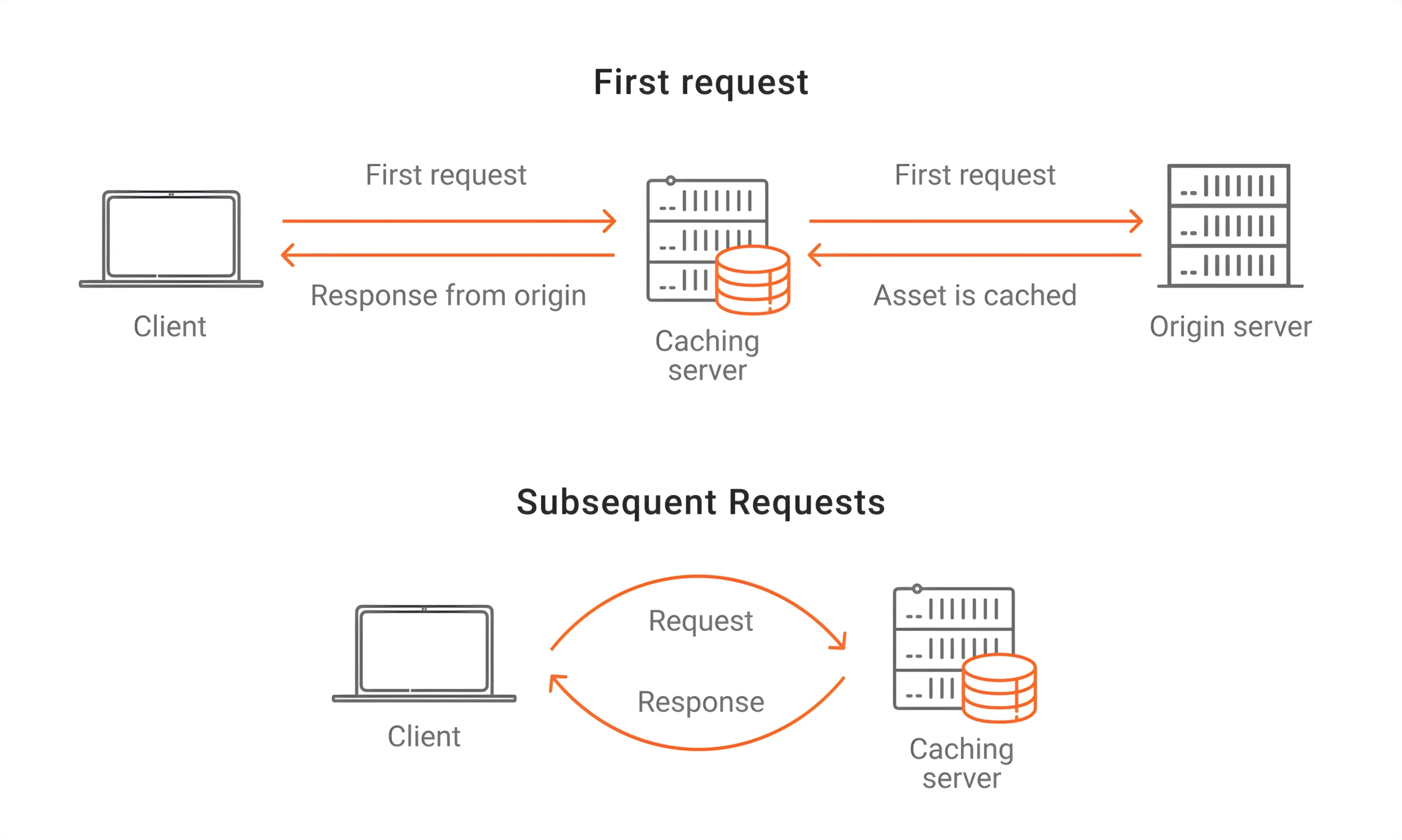
Typicky se cache vkládá mezi aplikační vrstvu a databázi. Aplikace si nejdřív ověří, zda už má požadovaná data uložená v cache. Pokud ne, sahá do databáze. Tím se dramaticky snižuje počet dotazů i latence odpovědí.
V praxi se nejčastěji používají paměťové cache systémy jako Redis nebo Memcached.
Caching se ale netýká jen dat z databáze. Ve škálovaných aplikacích se běžně ukládají také:
- výsledky drahých výpočtů,
- odpovědi API,
- uživatelské profily, konfigurace nebo oprávnění.
Velmi důležitá je přitom správná strategie expirace a neplatnost dat. Špatně nastavená cache sice zrychlí systém, ale může zároveň vracet neaktuální informace.
5) CDN – globální doručení obsahu
CDN (Content Delivery Network) slouží k tomu, aby se statický obsah webu (typicky obrázky, videa, CSS a JavaScript) doručoval uživatelům z geograficky nejbližšího uzlu, nikoli z jednoho centrálního serveru.
V praxi to znamená, že uživatel v Evropě stahuje data z evropského edge uzlu, uživatel v USA z amerického. Výsledkem je nižší latence a rychlejší načítání stránek, menší zátěž původních serverů a vyšší odolnost proti špičkám i výpadkům.
CDN funguje zároveň jako další vrstva cache. Pokud je obsah v edge uzlu dostupný, požadavek se vůbec nedostane na backendovou infrastrukturu. To je pro vysoce zatěžované aplikace zásadní.
V produkčním provozu se dnes nejčastěji používají globální CDN sítě jako Cloudflare, Akamai Technologies nebo Fastly.
Pro weby a aplikace s miliony uživatelů platí, že CDN už není jen optimalizace výkonu. Je to klíčová součást škálovací architektury, která odděluje doručování obsahu od samotné aplikační logiky a výrazně pomáhá zvládat globální provoz i nárazové kampaně.
6) Mikroslužby a design zaměřený na API
Architektura založená na microservices (mikroslužby) rozděluje aplikaci na menší, samostatné služby – například objednávky, platby, uživatele nebo vyhledávání. Každá služba má vlastní odpovědnost, vlastní životní cyklus a může se škálovat nezávisle na ostatních.
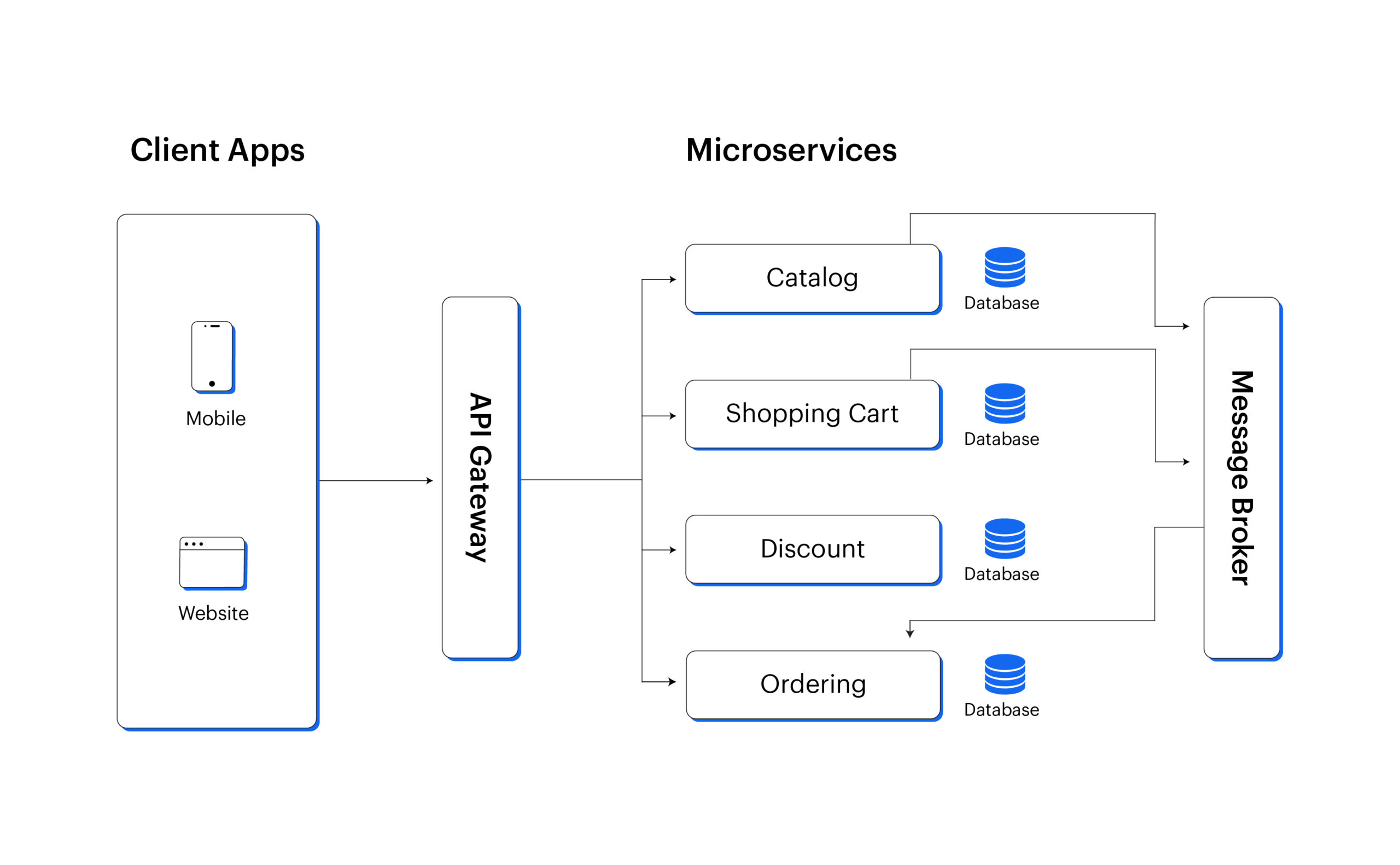
To je zásadní rozdíl oproti monolitu. Pokud je nejvíce zatížená jen jedna část systému (typicky vyhledávání nebo API pro mobilní aplikace), není nutné škálovat celý backend, ale pouze konkrétní službu.
API-first přístup znamená, že rozhraní mezi službami i směrem k aplikacím (web, mobil, partneři) je navržené od začátku jako primární kontrakt. Frontend i další systémy pak nestojí na interní logice aplikace, ale na stabilním a verzovaném API.
V praxi to přináší hlavně:
- možnost nezávislého vývoje a nasazování jednotlivých služeb,
- lepší škálování jen tam, kde skutečně vzniká zátěž,
- snadnější napojování mobilních aplikací, partnerů a externích služeb.
Mikroslužby a API-first architektura jsou dnes základním stavebním kamenem tzv. cloud-native přístupu, který zastřešuje například Cloud Native Computing Foundation.
Pro návrh samotných rozhraní je pak klíčový API-first přístup definovaný například iniciativou OpenAPI Initiative.
7) Monitoring a pozorovatelnost (observability)
U vysoce zatěžovaných aplikací už nestačí hlídat, jestli server běží. Klíčové je umět rychle pochopit, co se v systému děje a proč – tedy mít postavenou pozorovatelnost (observability).

Klasický monitoring vám typicky řekne, že se něco pokazilo. Pozorovatelnost jde o krok dál. Umožňuje pochopit, co přesně selhalo, kde v architektuře k problému došlo a jak spolu jednotlivé části systému souvisejí.
Moderní přístup stojí na třech typech dat:
- metriky – vytížení, latence, chybovost, propustnost,
- logy – detailní záznamy chování aplikací a služeb,
- trasování – průchod jednoho požadavku napříč celým systémem.
Právě distribuované trasování je zásadní ve chvíli, kdy aplikace běží jako soustava mikroslužeb a jeden uživatelský požadavek projde několika službami za sebou.
V praxi se velmi často používají nástroje jako Prometheus pro sběr metrik, vizualizační vrstva Grafana a standard pro sběr tras a telemetrie OpenTelemetry.
Pro škálované systémy má pozorovatelnost tři zásadní přínosy:
- umožňuje odhalit vznikající úzká místa ještě ve chvíli, kdy se jejich dopad neprojevil na uživatelské zkušenosti,
- výrazně zrychluje řešení incidentů a výpadků,
- dává podklady pro správné nastavení auto-scalingu a kapacit.
Monitoring a observability dnes rozhodují o tom, zda dokáže tým infrastrukturu skutečně řídit, nebo ji jen hasí ve chvíli, kdy už je problém vidět i zvenku.
Praktické kroky pro nasazení
- Začněte s jednoduchou architekturou – monolit nebo dvě vrstvy (aplikace + databáze).
- Implementujte load balancer a CDN hned od začátku.
- Automatizujte škálování a nasazování pomocí CI/CD a autoscaling pravidel.
- Testujte výkon zátěžovými testy – zjistěte, kde jsou slabá místa.
- Postupně zvažte mikroslužby, pokud aplikace roste nad milion uživatelů.
Škálování je dnes hlavně o architektuře, ne o větším serveru
Růst na statisíce a miliony uživatelů stojí na kombinaci vrstev – load balancingu, auto-scalingu, databázové architektury, cache, CDN a observability. Teprve jejich propojení umožňuje růst bez výpadků a zbytečných nákladů.
Pro české týmy je navíc důležité i kde a kým je infrastruktura provozována. Dává proto smysl stavět produkční prostředí na české infrastruktuře ZonerCloud, na kterou navazuje správa domén a DNS přes CZECHIA.COM a automatizace certifikátů pomocí SSLMarketu.
Výsledkem je prostředí, které umožňuje automatizaci, podporuje škálování bez ručních zásahů a dává týmu dlouhodobou kontrolu nad bezpečností i provozem.







