Obsah
Související




Jazykový model je pravděpodobnostní model přirozeného jazyka, který dokáže předpovídat, jaká slova nebo sekvence slov budou následovat na základě předchozího textu. Jednoduše řečeno, je to systém, který se naučil, jak funguje lidský jazyk, a dokáže s ním pracovat – ať už jde o doplňování textu, odpovídání na otázky, překlad mezi jazyky nebo vytváření nového obsahu.
A ano, i váš mobilní telefon, když opravuje překlepy nebo nabízí dokončení rozepsaných slov, používá jednoduchý jazykový model. Takže když příště budete psát zprávu a telefon vám nabídne dokončení slova, můžete si říct: „Aha, teď mi asistuje jazykový model!“ – i když samozřejmě mnohem jednodušší než ty, které pohánějí nejmodernější AI systémy.
Krátká historie jazykových modelů
Historie jazykových modelů sahá do poloviny 20. století, kdy lingvisté a informatici začali zkoumat, jak by počítače mohly pracovat s lidským jazykem. První jazykové modely byly velmi jednoduché a založené na pravidlech – programátoři museli ručně definovat gramatická pravidla a slovní zásobu.
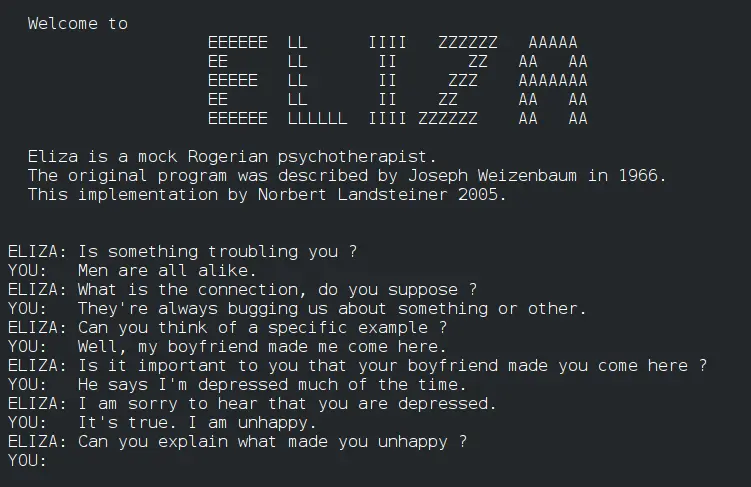
První počítačový program pro zpracování přirozeného jazyka ELIZA, který byl vyvíjen v letech 1964 až 1967 na MIT Josephem Weizenbaumem. (zdroj)
V 80. a 90. letech se začaly prosazovat statistické jazykové modely, které analyzovaly velké množství textů a počítaly pravděpodobnosti výskytu slov a jejich kombinací. Tyto modely už nebyly založené na pevných pravidlech, ale na statistických vzorcích objevených v datech.
Skutečný průlom přišel kolem roku 2018 s nástupem velkých jazykových modelů (LLM) založených na neuronových sítích a architektuře zvané transformer. Tyto modely, jako je GPT (Generative Pre-trained Transformer), BERT nebo LLaMA, jsou trénované na obrovském množství textů z internetu, knih a dalších zdrojů, a dosahují bezprecedentní schopnosti porozumět a generovat text podobný lidskému.
Rozdíl mezi statistickým modelem a velkým jazykovým modelem (LLM)
Statistický jazykový model
Představte si, že se učíte cizí jazyk a zapisujete si, jak často se která slova vyskytují po sobě. Po čase byste mohli říct: „Když někdo řekne ‚dobrý‘, v 80 % případů následuje slovo ‚den‘.“ Přesně takto fungují statistické jazykové modely – počítají pravděpodobnosti výskytu slov na základě toho, co viděly v trénovacích datech.
Typickým příkladem je tzv. n-gramový model, který sleduje sekvence n po sobě jdoucích slov. Například bigramový model (n=2) by mohl zjistit, že po slově „České“ často následuje „republiky“, a trigramový model (n=3) by mohl zachytit, že po „hlavní město České“ často následuje „republiky“.

Statistické modely jsou relativně jednoduché a výpočetně nenáročné, ale mají značná omezení:
- Nedokáží zachytit význam na dlouhé vzdálenosti v textu
- Nerozumí kontextu mimo svůj omezený „pohled“ několika slov
- Mají problém s neobvyklými, ale gramaticky správnými větami
Velký jazykový model (LLM)
Moderní velké jazykové modely jsou založené na neuronových sítích s architekturou transformer a obsahují miliardy nebo dokonce biliony parametrů (vah). Na rozdíl od statistických modelů:
- Dokáží zachytit komplexní vzory a závislosti v jazyce na dlouhé vzdálenosti
- Rozumí širšímu kontextu a mohou udržet konzistenci napříč dlouhým textem
- Jsou schopné „porozumět“ abstraktním konceptům a generovat kreativní, koherentní text
- Mohou provádět různorodé úkoly bez specifického přetrénování pro každý úkol
Představte si to jako rozdíl mezi člověkem, který se naučil několik frází v cizím jazyce (statistický model), a někým, kdo daný jazyk skutečně ovládá, rozumí jeho nuancím a dokáže v něm tvořit (LLM).
Klíčové pojmy
Token
Když pracujeme s jazykovými modely, často narazíme na pojem „token“. Token je základní jednotka, se kterou model pracuje – něco jako stavební kámen textu. V nejjednodušším případě může být tokenem jedno slovo, ale často to bývají i části slov, interpunkční znaménka nebo speciální symboly.
Například věta „Mám rád zmrzlinu.“ by mohla být rozdělena na tokeny: [„Mám“, „rád“, „zmrzl“, „inu“, „.“]

Proč je to důležité? Jazykové modely mají omezení na počet tokenů, které mohou zpracovat najednou – tento limit se nazývá „kontextové okno„. Čím větší je toto okno, tím delší text může model najednou „vidět“ a zpracovat.
Trénovací data
Jazykové modely se učí z trénovacích dat – obrovských souborů textů, které mohou zahrnovat knihy, články, webové stránky, konverzace a další textové zdroje. Kvalita a rozmanitost těchto dat významně ovlivňuje schopnosti modelu.
Moderní LLM jsou trénovány na stovkách gigabajtů nebo dokonce terabajtů textových dat, což odpovídá miliardám až bilionům slov. Například GPT-3 byl trénován na datech o velikosti přibližně 45 TB, což je ekvivalent přibližně 500 miliard tokenů. U GPT-4 se předpokládá násobně větší množství trénovacích dat.
Je to trochu jako kdyby někdo přečetl miliony knih a článků a snažil se z nich naučit, jak funguje jazyk a o čem lidé píší. Čím více různorodých textů model „přečte“, tím lépe dokáže generovat smysluplné a relevantní odpovědi.
Kontext
Kontext je klíčový koncept pro pochopení moderních jazykových modelů. Jednoduše řečeno, kontext je „paměť“ modelu – text, který model vidí a na jehož základě generuje odpověď.
Když komunikujete s jazykovým modelem, vše, co jste dosud napsali a co model odpověděl, tvoří kontext pro jeho další odpověď. Čím delší a bohatší je tento kontext, tím lépe může model porozumět vašemu záměru a poskytnout relevantní odpověď.
Představte si to jako rozhovor s člověkem – pokud si pamatuje, o čem jste se bavili před pěti minutami, může na to navázat. Pokud by si pamatoval jen poslední větu, rozhovor by byl velmi omezený. Moderní LLM mají výhodu v tom, že dokáží pracovat s mnohem delším kontextem než starší modely.
Velikost kontextového okna se u různých modelů výrazně liší a je jedním z klíčových parametrů při srovnávání jejich schopností:
- Claude 3 od společnosti Anthropic má kontextové okno až 200 000 tokenů, což je ekvivalent přibližně 150 000 slov nebo asi 400-500 stran textu. To umožňuje modelu „přečíst“ celou knihu najednou.
- GPT-4o od OpenAI, Gemini od Google a Llama 3 od Meta mají kontextové okno kolem 128 000 tokenů (přibližně 100 000 slov nebo 250-300 stran textu).
- Starší modely jako GPT-3 měly kontextové okno pouze 4 096 tokenů, což je přibližně 3 000 slov nebo 7-8 stran textu.
Tyto rozdíly jsou důležité v praxi – model s větším kontextovým oknem může analyzovat delší dokumenty, udržet konzistenci v dlouhých konverzacích a lépe porozumět komplexním zadáním s mnoha detaily.
Kde se jazykové modely používají
Jazykové modely dnes najdeme v mnoha aplikacích a službách, se kterými se běžně setkáváme:
- Vyhledávače – pomáhají lépe porozumět vašim dotazům a poskytovat relevantnější výsledky
- Překladače – jako je Google Translate nebo DeepL, které využívají jazykové modely pro překlad mezi jazyky
- Textové editory – nabízejí kontrolu pravopisu, gramatiky a návrhy na dokončení textu
- Virtuální asistenti – jako je Siri, Alexa nebo Google Assistant
- Chatboti a zákaznická podpora – automatizované systémy, které dokáží odpovídat na dotazy zákazníků
- Generování obsahu – od článků a shrnutí po kreativní psaní a poezii
- Kódování a programování – asistenti jako GitHub Copilot, kteří pomáhají programátorům psát kód
A samozřejmě, když váš textový editor na mobilu navrhuje, co byste mohli napsat dál, nebo automaticky opravuje překlepy, také využívá (byť jednodušší) jazykový model. Je to jako mít malého jazykového pomocníka přímo v kapse!
Jazykové modely představují fascinující oblast umělé inteligence, která se rychle vyvíjí. Od jednoduchých statistických modelů jsme se dostali k pokročilým neuronálním sítím, které dokáží generovat text téměř k nerozeznání od lidského. Tyto technologie mění způsob, jakým interagujeme s počítači, a otevírají nové možnosti v mnoha oblastech.








