Jak na vlastní katalog stránek v PHP – příprava




Dnes na Internetu najdete řadu více či méně zdařilých portálů, jejichž společným jmenovatelem je katalog stránek. Možná jste přemýšleli nad tím, jak byste si mohli sami nějaký katalog stránek (odkazů) vyvinout. V několika článcích vás povedu krok za krokem s vývojem informačního systému na konkrétním zadání, které si zadefinujeme. Dnešní článek bude trochu teoretičtější, další pak už budou praktické.
Úvodem
Než začnu blíže mluvit o vlastním vývoji, zmíním ještě několik základních poznámek. Přemýšlel jsem, na jaké platformě budu ukazovat konkrétní příklady, a nakonec jsem se rozhodl pro nejdostupnější databázi MySQL a skriptovací jazyk PHP. Z jistých důvodů už na začátku udávám, v jakém prostředí se budeme pohybovat, ale ve skutečnosti volba databáze a jazyka není prvním krokem při vývoji informačního systému.
Pro následující čtení článků předpokládám znalost jazyka SQL na úrovni článků, které již na Intervalu vyšly a dále předpokládám základní znalost PHP (opět na úrovni článků vydaných Intervalem).
Výběr vhodné databáze a programovacího nástroje je klíčovým momentem. Je třeba pečlivě zvážit, který systém (rozuměj databáze+programovací jazyk) je pro nás nejvýhodnější, jaké vlastnosti nám nabízí a jaké funkce jsou nám dostupné. Dalším aspektem je také rychlost zpracování (časová složitost) a možný objem zpracovávaných dat (prostorová složitost). Další kritéria na výběr systému mohou spočívat v možnostech zálohování, obnovy dat po havárii, údržba celého systému apod. V neposlední řadě je nutné si položit otázky typu:
- Kolik uživatelů denně bude přistupovat na náš systém?
- Kolik záznamů bude náš informační systém potřebovat uchovávat?
- Má náš systém běžet 24 hodiny denně, 7 dní v týdnu?
- Odkud budou uživatelé k systému přistupovat?
To je jen malý nástin otázek, které si musíte položit a které mohou zásadně ovlivnit volbu platformy, databáze, jazyka, hardwaru a mnoha jiného.
O vývoji obecně
Předem se omlouvám se rozsáhlejší úvod, ale dříve, než přikročíme k vlastnímu zadání našeho informačního systému, který chceme vyvíjet, uvedu trochu základní teorie.
V klasickém pojetí vývoje informačního systému, lze vývoj rozdělit do několika fází:
- Analýza – sběr základních informací a požadavků na systém, formování zadání informačního systému na základě komunikace s koncovým uživatelem (zákazníkem)
- Návrh datové základny a volba systému – návrh databázových tabulek, volba platformy, databázového systému, programovacího nástroje a hardwaru
- Implementace systému – naprogramování IS podle požadavků uživatele v dohodnuté době
- Nasazení systému do zkušebního provozu – ladění, odstraňování chyb
- Ostrý provoz
- Údržba systému, eventuelní vylepšování systému (nové verze)
V tomto a dalších článcích se budu věnovat hlavně prvním třem bodům. Jak sami vidíte, jednotlivé části na sebe navazují (není to tak úplně pravda, ve skutečnosti se mohou některé fáze vzájemně překrývat). Obecně platí, že čím později narazíme na chybu, tím víc nás to bude stát. Jinými slovy, ze vzrůstajícím počtem již provedených fází, vzrůstají i náklady spojené s opravou, či přepracováním celého informačního systému.
Podotýkám, že toto je jeden z možných způsobů, jak vyvíjet informační systém. Existuje jich celá řada, zde uvedený je nejpřirozenější.
Zadání systému
Nyní si nadefinujme, co všechno bude náš katalog stránek (nad kterým můžeme v budoucnu vystavět celý portál) umět a co bude návštěvníkům nabízet. Tímto vstupujeme do první fáze vývoje. Tato část se skládá hlavně z diskusí s koncovými uživateli, aby nám formou odpovědí na naše otázky řekli, co od našeho informačního systému očekávají, jaké služby tam chtějí mít, apod. Důležitá je i věková skupina uživatelů, neboť zcela jistě budeme například volit jiný design stránek pro mládež do dvaceti let a jiný pro populaci nad čtyřicet let. Výsledkem sběru všech dostupných informací a diskusí je formování zadání, které řekněme, bude vypadat takto:
Vyvinout jednoduchý katalog stránek, který bude v jednotlivých sekcích a v nich vnořených podsekcích sdružovat jednotlivé odkazy. Uživatel bude mít možnost jednotlivé sekce procházet. Nad odkazy bude možné provádět základní a rozšířené vyhledávání. Uživatel bude smět přidat odkaz na stránku, zrušit odkaz na stránku, který sám přidal, nebo editovat jim přidaný odkaz. Na stránkách bude u každého odkazu možnost hlasování o kvalitě stránky a dále informace, zda-li je stránka dostupná. Tato vlastnost se uplatní, pokud si uživatel o to explicitně požádá. Systém bude také nabízet základní statistiky dle různých hledisek.
To bude zatím základní zadání, kterého se budeme držet. Později možná rozšíříme systém i o další zajímavé funkce. Jak už jsme řekli, vyvíjet systém budeme nad databází MySQL a jako programovací jazyk jsme si zvolili PHP. V žádném případě ale neočekávejte, že po přečtení všech dílů tohoto miniseriálu, budete mít po přetažení všech ukázek zdrojových kódů celý katalog (v podstatě budete mít k dispozici jen „hrubou“ kostru zdrojového kódu katalogu). Těmito články chci poukázat na klíčové momenty, podat výklad o dané problematice a podložit jej praktickou ukázkou skriptu. To jenom na upřesnění, aby někteří nebyli zklamáni z toho, že očekávali něco jiného. Berte tuto sérii článků jako návod. Nakonec reálné zadání se bude od našeho zadání zcela jistě lišit.
Návrh datové základny
Nyní přistupme k návrhu datového modelu. Musíme si přesně určit, jaké informace si potřebujeme vést v databázi. Při konstrukci datového modelu musíme samozřejmě vyjít ze zadání. Podotýkám, že návrh datové základny je jeden z nejdůležitějších okamžiků při vývoji informačního systému.
Ze zadání plyne, že jedny ze základních objektů bude SEKCE a ODKAZ. Jaké informace (tj. jaké atributy) o nich chceme evidovat? Začněme ODKAZem. U odkazu nás bude zajímat NÁZEV, URL, POPIS, KVALITA_STRÁNKY, KDO a KDY stránku přidal a pod jakým HESLEM (kvůli budoucímu zrušení nebo editování odkazu). Nakonec musíme ještě evidovat, do jaké sekce je odkaz začleněn (SEKCE_ID). U sekce bude informací méně. Potřebujeme vědět NÁZEV sekce, eventuelně její POPIS, kolik odkazů je v ní uloženo (POČET) a kdy byla sekce založena. Pro budoucí zjednodušení implementace se nám bude hodit mít u každé sekce poznamenáno, zdali se jedná o hlavní sekci, tj. která již nemá žádnou nadřazenou. Tento atribut nazvěme KOŘEN (kořenová sekce).
Sekce jsou ve vzájemném vztahu: nadsekce – podsekce. Tím vlastně sekce tvoří stromovou strukturu, jak ukazuje příklad na následujícím obrázku:
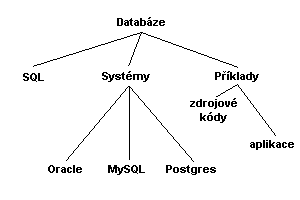
Uvážíme-li, že každá sekce bude mít vnitřně v databázi své číslo, např. (1-Databáze, 2-SQL, 3-Systémy, 4-Příklady, 5-Oracle, 6-MySQL, atd.), můžeme využít novou tabulku VAZBY_SEKCE, která bude přesně kopírovat onu stromovou strukturu. Atributy budou číslo nadsekce a číslo podsekce , ve kterých budou vystupovat právě čísla sekcí, které jsou ve vzájemném vztahu:
|
První řádek této tabulky říká, že sekce číslo 1 je nadsekcí sekce číslo 2. Druhý řádek říká, že tatáž sekce číslo 1 je nadsekcí také sekci číslo 3. Je zde evidentně vztah 1:N. Takto reprezentované vztahy mezi sekcemi jsou navrženy dobře, neboť z této tabulky (byť to nemusí být na první pohled zřejmé) dokážeme vždy zjistit jaké podsekce má sekce zadaného čísla, do jaké nadsekce je zařazena konkrétní sekce, a nakonec nám tabulka pomůže ke zpětnému vygenerování „cesty“ všech postupně nadřazených sekcí, např.:
Databáze ~ Systémy ~ MySQL
Tj. měli jsme číslo sekce „MySQL“ a postupně jsme se dopracovali k tomu, že hlavní sekcí (tj. ta co už nemá žádnou nadřazenou) je sekce „Databáze“. Tolik jenom na vysvětlenou, jak to vypadá se sekcemi. Pojďme dál.
Vraťme se ještě k odkazům. Řekli jsme, že odkaz je vždy zařazen v nějaké sekci. Pro jednoduchost budeme předpokládat, že odkaz může být zařazen právě v jedné sekci (i když v praxi bývá zvykem odkaz zařadit do více sekcí). Díky tomuto omezení nemusíme zakládat novou tabulku, ale bude nám stačit mít v tabulce ODKAZ atribut SEKCE_ID, který bude obsahovat právě číslo sekce, ve které je odkaz zařazen.
V zadání máme napsáno, že nad odkazy má být realizováno vyhledávání. Zcela jistě budeme chtít vyhledávat bez ohledu na velikost písmen a i bez ohledu na diakritiku. S ignorováním diakritiky v MySQL při dotazech je obecně problém. Proto si v tabulce ODKAZ zavedeme ještě jeden atribut TEXT_ASCII, který bude obsahovat od diakritiky ořezaný řetězec složený z názvu a popisu odkazu. K bližšímu popisu, jak to bude celé fungovat se dostanu až v díle, kde budu podrobněji psát o vyhledávání. Jde o to, že vyhledávat budeme nad tím textem bez diakritiky a do výsledku budeme pak vracet text s diakritikou.
Jak jsme řekli, uživatel má možnost přidat odkaz. Samozřejmě přidávaný odkaz neuložíme hned do tabulky ODKAZ, ale půjde do speciální tabulky. Nazvěme si ji ŽÁDOSTI. Ta bude mít obdobnou strukturu, a budou v ní uloženy nově přidané, dosud nezařazené odkazy do databáze. Správce systému bude mít pak nástroj, kterým bude moci nové odkazy zařadit do tabulky ODKAZ a zároveň je z tabulky ŽÁDOSTI vymazat.
Vytvoření tabulek
Nyní ukáži SQL skript, kterým vytvoříme potřebnou databázi, včetně jejich tabulek. Ze skriptu vyčtete, jakých typů jsou jednotlivé atributy a jaká mají integritní omezení. Rovněž lze vyčíst, co jsou primární klíče a co jsou cizí klíče. Naše databáze se bude jmenovat KATALOG a o její vytvoření a používání se postarají první dva příkazy skriptu.
|
Tento skript nám vytvoří 4 základní tabulky, se kterými budeme zatím pracovat. Postupně, podle potřeby, nadefinujeme eventuálně tabulky další.
Věřím, že dnes bylo na vás informací velmi mnoho. Další povídání budu tedy situovat do příštího dílu, ve kterém se budeme věnovat implementaci zobrazení úvodní stránky katalogu.
Starší komentáře ke článku
Pokud máte zájem o starší komentáře k tomuto článku, naleznete je zde.







