
5 způsobů, jak zlepšit nastavení webového aplikačního serveru
Obsah
Související



Když máte hotovou nějakou aplikaci a jste připraveni dát ji do ostrého provozu v prostředí cloud serveru, možná by vás zajímalo, jak by se dalo serverové prostředí vylepšit tak, aby učinilo skok ze stavu „funguje“ na úroveň plnohodnotného produkčního prostředí. Tento článek pomůže v začátcích plánování a implementace produkčního prostředí tím, že vytvoříme volnou definici „produkčního prostředí“ v kontextu webové aplikace, která se nachází v prostředí cloud serveru, a předvedeme některé komponenty, které můžete dodat do existující architektury, abyste tento přechod uskutečnili.
Abychom to předvedli prakticky, předpokládejme, že jsme začali s nějakou konfigurací podobnou té, která se popisuje v článku Pět běžných serverových konfigurací, jakou je například toto prostředí složené ze dvou serverů obsluhujících nějakou webovou aplikaci:
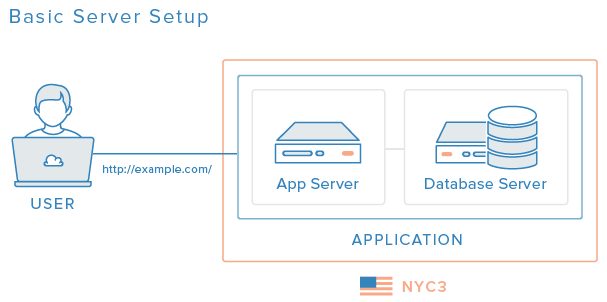
Vaše skutečná konfigurace může být jednodušší nebo složitější, všeobecné ideje a komponenty, které zde budeme probírat, by ale měly být do jisté míry aplikovatelné na jakékoli serverové prostředí.
Začneme tím, že budeme definovat, co rozumíme slovním spojením „produkční prostředí“.
Co je produkční prostředí?
Serverové prostředí pro nějakou webovou aplikaci, myšleno všeobecně, se skládá z hardwaru, softwaru, dat, operačních plánů a personálu nezbytně nutných k tomu, aby aplikace fungovala. Produkčním prostředím se obvykle odkazujeme na nějaké serverové prostředí, které bylo navrženo a implementováno s cílem zajistit co nejlepší přijatelnou úroveň následujících faktorů:
- Dostupnost (availability). Způsobilost aplikace být používána uživateli, pro které je určena, během daných hodin jejího provozu. Dostupnost může být přerušena jakýmkoli selháním, které dostatečně závažně ovlivní některou z kritických komponent (např. aplikace spadne kvůli nějaké chybě, přestane fungovat zařízení databázového úložiště, nebo systémový administrátor z ničehož nic vypne aplikační server). Jedním ze způsobů, jak posilovat dostupnost, je snižovat v prostředí počet částí, jejichž selhání zapříčiní selhání celého systému (tzv. SPOF, single point of failure).
- Zotavitelnost (recoverability). Způsobilost serveru zotavit aplikační prostředí, pokud dojde k selhání systému nebo ke ztrátě dat. Pokud přestane fungovat kritická komponenta, kterou nelze zotavit, přestane existovat dostupnost. Vylepšováním udržovatelnosti (maintainability), což je příbuzný pojem, se redukuje v případě selhání doba potřebná na provedení patřičného zotavovacího procesu, a proto může v případě selhání zlepšit dostupnost.
- Výkonnost (performance). Aplikace funguje podle očekávání při průměrném zatížení i ve špičkách (např. reaguje přiměřeně rychle). Přestože pro uživatele je velmi důležitá, záleží na ní jen tehdy, pokud je aplikace dostupná.
Věnujme teď trochu času k určení v kontextu aplikace přijatelné úrovně všech právě uvedených prvků. Budou velmi odlišné v závislosti na důležitosti a povaze aplikace, pro kterou je stanovujeme. Například, pro nějaký osobní blog, který obsluhuje jen nevelký počet návštěvníků, lze patrně akceptovat, že má občas prostoje nebo chabou výkonnost, hlavní je, aby ho vždy bylo možné zotavit. Online obchod nějaké firmy však musí usilovat ve všech kategoriích o co nejlepší ukazatele. Bylo by samozřejmě pěkné docílit ve všech kategoriích a pro všechny aplikace sta procent, to však často není proveditelné kvůli časovým nebo finančním limitům.
Připomeňme ještě, že jsme jako faktory nezmínili (a) spolehlivost (reliability) hardwaru, což je pravděpodobnost, že daná hardwarová komponenta předčasně neselže, že bude řádně fungovat po celou předem stanovenou dobu, (b) bezpečnost. Je tomu tak proto, že předpokládáme (a) že cloudové servery, které používáte, jsou obvykle dostatečně spolehlivé, i když mají potenciál selhat (protože běží na fyzických serverech), (b) že dodržujete nejlepší bezpečnostní praktiky tak, jak nejlépe umíte — řečeno prostě, oba faktory se nacházejí vně rámce tohoto článku. Musíte si však být vědomi toho, že spolehlivost a bezpečnost jsou faktory, které mohou mít přímý vliv na dostupnost, a oba mohou zvyšovat potřebu zotavitelnosti.
Postup, jak se vytvoří produkční prostředí, nebudeme uvádět ve stylu krok za krokem, protože to není možné vzhledem k variabilitě potřeb a povah jednotlivých aplikací. Představíme raději některé hmatatelné komponenty, jichž můžete využít při transformaci existující konfigurace na produkční prostředí.
Pojďte se na tyto komponenty podívat!
1. Zálohovací systém
Zálohovací systém garantuje způsobilost vytvářet pravidelně zálohy (backups) dat a ze záloh data obnovovat. Zálohy také umožňují vracet data do nějakého dřívějšího stavu (tzv. rollback) v případě, že byla omylem vymazána nebo nežádoucím způsobem modifikována, k čemuž může dojít z mnoha různých důvodů, včetně lidské chyby. Veškerý počítačový hardware může v některém okamžiku selhat, což může potenciálně způsobit ztrátu dat. Je ve vašem bytostném zájmu udržovat nejnovější zálohy všech důležitých dat.
Požaduje se pro produkční prostředí? Ano. Zálohovací systém může zmírnit účinky ztráty dat, což je nezbytné, chceme-li docílit zotavitelnosti, a posílit tedy dostupnost v případě, že dojde ke ztrátě dat — musí se však používat v součinnosti se solidními zotavovacími plány, které probereme v příští sekci. Poznamenejme, že zálohy DigitalOcean založené na momentkách (snapshots), nemusejí být pro zálohovací potřeby postačující, protože se příliš nehodí pro zálohování aktivních databází nebo jiných aplikací s vysokým diskovým zapisovacím I/O (vstupem a výstupem) — pokud provozujete tyto typy aplikací, nebo chcete mít flexibilnější zálohovací rozvrh, určitě použijte nějaký jiný zálohovací systém, jako je Bacula.
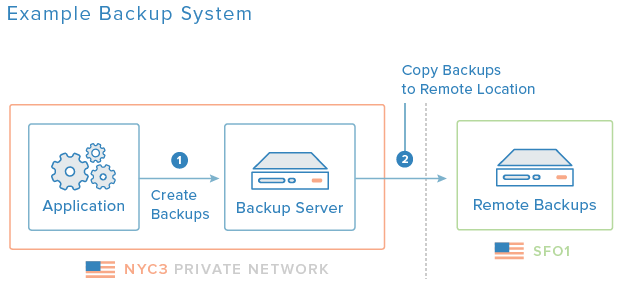
Výše uvedený diagram je ukázka základního zálohovacího systému. Zálohovací server sídlí ve stejném datovém centru jako aplikační servery, kde se vytvářejí počáteční zálohy. Později, se mimo oblasti dění dělají kopie záloh na nějaký server v jiném datovém centru, aby bylo zajištěno, že se data uchovají i v případě, řekněme, nějaké přírodní katastrofy.
Co je třeba promyslet?
- Výběr dat. Která data budete zálohovat. Přinejmenším zálohujte všechna data, která nemůžete spolehlivě reprodukovat z nějakého alternativního zdroje.
- Rozvrh zálohování. Kdy a jak často budete pořizovat úplné nebo inkrementální zálohy. Musíte také zvlášť posoudit, jak zálohovat speciální typy dat, mezi něž patří aktivní databáze, což může ovlivňovat rozvrh zálohování.
- Retenční perioda dat. Jak dlouho budete udržovat zálohovaná data, než je vymažete.
- Diskový prostor pro zálohy. Tři předchozí položky mají vliv na to, jak velký diskový prostor bude zálohovací systém vyžadovat. Využívejte komprimaci a inkrementální zálohy, abyste snížili velikost diskového prostoru potřebného pro zálohy.
- Kopie dělejte jinde. Abyste zálohy ochránili proti lokálním katastrofám v místě konkrétního datového centra, je moudré udržovat kopii záloh na zeměpisně jiné lokaci. Na diagramu výše se pro tento účel zálohy z NYC3 kopírují na SFO1.
- Testy obnovy ze záloh. Pravidelně testujte proces obnovy ze záloh, abyste si byli jisti, že zálohování pořád funguje řádně.
2. Zotavovací plány
Zotavovací plány tvoří sada zdokumentovaných postupů, jak se uvnitř produkčního prostředí zotavovat z potenciálních selhání nebo administračních chyb. Holým minimem je mít nějaký zotavovací plán pro každý paralyzující scénář, o němž se domníváte, že k němu nevyhnutelně jednou dojde, jako že selže hardware serveru nebo se nepředvídatelně vymažou nějaká data. Například, primitivní zotavovací plán pro případ selhání serveru by mohl tvořit seznam kroků, které jste podnikli, když jste poprvé umisťovali server (tzv. server deployment), plus všechny další postupy pro obnovu aplikačních dat ze záloh. Lepší zotavovací plán by kromě dobré dokumentace těžil z umisťovacích skriptů (deployment scripts) a nástrojů pro správu konfigurace, jako jsou Ansible, Chef nebo Puppet, protože ty pomáhají proces zotavení automatizovat a urychlit.
Požadují se pro produkční prostředí? Ano. Přestože zotavovací plány neexistují v serverovém prostředí jakožto software, jsou nezbytnou komponentou produkční konfigurace. Umožňují účinně využívat zálohy, které pořizujete, a slouží jako nástin programu, jak znovu vybudovat prostředí, nebo ho vrátit do žádoucího předchozího stavu, pokud bude třeba takovou akci provést.
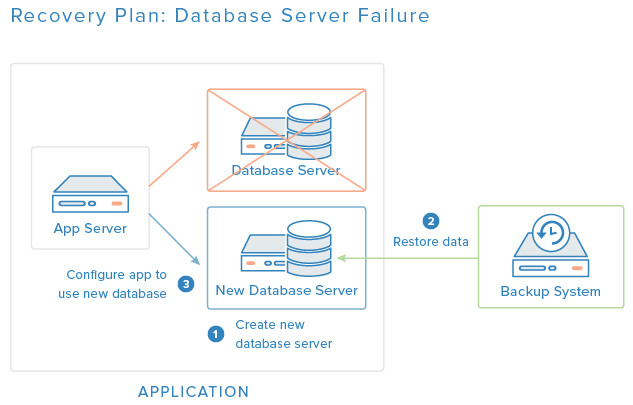
Výše uvedený diagram je nástin zotavovacího plánu, pro případ, že selže databázový server. V tomto případě se původní databázový server nahradí novým, který bude mít nainstalovaný stejný software, a k obnově serverové konfigurace a dat se použije poslední dobrá záloha. Nakonec se nakonfiguruje aplikační server tak, aby používal nový databázový server.
Co je třeba promyslet?
- Dokumentace postupů. Sada dokumentů obsahujících postupy, kterých bude nutné se držet, pokud dojde k nějakému selhání. Dobrým výchozím bodem je sestavit nějaký dokument s pokyny ve stylu krok za krokem, jak postupovat, abyste znovu vybudovali zhavarovaný server. Pak přidáte kroky pro obnovu rozličných aplikačních dat a konfigurace ze záloh.
- Automatizační nástroje. Skripty a software pro správu konfigurace umožňují postupy automatizovat, a tím zlepšovat umisťovací a zotavovací procesy. Přestože průvodci ve stylu krok za krokem jsou často adekvátní k tomu, aby se dalo jednoduše zotavit z nějakého selhání, musí tyto kroky vykonat člověk, proto nejsou ani tak rychlé, ani tak konsistentní jako automatizovaný proces.
- Kritické komponenty. Jsou to komponenty, bez nichž aplikace nemůže řádně fungovat. V příkladu uvedeném výše jsou kritickými komponentami jak aplikace, tak i databázové servery, protože pokud selže to či ono, aplikace se stane nedostupnou.
- SPOF (Single Points of Failure). Jedná se o kritické komponenty, které nemají automatický mechanizmus zvaný failover (přepnutí na redundantní zařízení), takže pokud selžou, přestane fungovat celý systém. Takové komponenty byste měli ze všech svých sil eliminovat, abyste zlepšili dostupnost.
- Revize. Jakmile nějak vylepšíte umisťovací a zotavovací procesy, aktualizujte dokumentaci.
3. Vyvažování zátěže
Vyvažování zátěže se přidává do serverového prostředí proto, aby se zvýšila výkonnost a dostupnost tím, že se pracovní zátěž rozloží na více serverů. Pokud selže jeden ze serverů, které se podílejí na vyvažování zátěže, ostatní servery převezmou a budou zpracovávat provoz přicházející na tento server, dokud se „nemocný“ server neuzdraví. V prostředí cloud serveru, se vyvažování zátěže typicky implementuje tak, že se přidá server (tzv. load balancer), který provozuje software pro vyvažování zátěže (reverzní proxy server) před ostatními servery, které provozují konkrétní komponentu nějaké aplikace.
Požaduje se pro produkční prostředí? Nezbytně nutné není. Vyvažování zátěže se nepožaduje pro všechna produkční prostředí, pokud se však implementuje korektně, může představovat účinný způsob, jak v systému redukovat počet SPOF (single points of failure). Může také zlepšit výkonnost, protože se prostřednictvím horizontálního škálování přidává kapacita navíc.
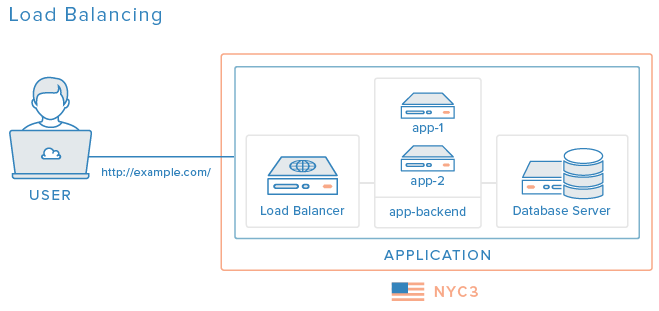
Ve výše uvedeném diagramu se přidává dodatečný aplikační server, aby sdílel zátěž, a server pro vyvažování zátěže (load balancer), který rozloží uživatelské požadavky na oba aplikační servery. Tato konfigurace může pomoci s výkonem, pokud se s veškerým provozem usiloval vypořádat jen jediný aplikační server, a může také pomoci s tím, aby aplikace zůstala dostupná, pokud selže jeden z aplikačních serverů. Pořád tu však máme dvě komponenty charakteru SPOF, databázový server a samotný server určený pro vyvažování zátěže.
Co je třeba promyslet?
- Komponenty, u nichž je možné vyvažovat zátěž. U některých komponent v prostředí vyvažovat zátěž není snadné. Pořádně promyslet to musíte u jistých druhů softwaru, mezi něž patří databáze nebo stavové aplikace.
- Replikace aplikačních dat. Pokud aplikační server, u něhož se vyvažuje zátěž, ukládá aplikační data lokálně (na místě), například nahrávané soubory, musejí být tato data dostupná ostatním aplikačním serverům prostřednictvím vhodných metod, jako jsou replikace nebo sdílené souborové systémy. Je to nezbytné, protože je třeba zajistit, aby byla aplikační data dostupná bez ohledu na to, který aplikační server byl zvolen k obsluze uživatelského požadavku.
- Úzká hrdla výkonu. Pokud nemá server určený pro vyvažování zátěže dostatek zdrojů, nebo není řádně nakonfigurovaný, může naopak snižovat výkon aplikace.
- SPOF. Přestože se pomocí vyvažování zátěže mohou eliminovat kritické komponenty způsobující selhání celého systému (SPOF), když se naplánuje špatně, mohou se tím přidat další SPOF.
4. Monitorování
Monitorování může být oporou serverového prostředí tím, že eviduje stav služeb a sleduje trendy využívání serverového zdroje. Poskytuje tedy skvělý vhled do daného prostředí. Jedním z největších benefitů monitorovacích systémů je možnost nakonfigurovat je tak, aby spouštěly nějakou akci, když spadne nějaká služba nebo server, nebo když se některý ze zdrojů, jako jsou CPU, paměť nebo úložiště stane přetíženým. Mohou například spustit nějaký skript nebo odeslat notifikaci. Notifikace umožňují reagovat na jakékoli potíže hned, jak nastanou, což může pomoci minimalizovat prostoje aplikace, nebo jim zabránit.
Požaduje se pro produkční prostředí? Nezbytně nutné není, potřeba monitorovat se však zvyšuje, jak narůstá velikost a složitost produkčního prostředí. Poskytuje snadný způsob, jak sledovat kritické služby a serverové zdroje. Monitorováním pak zase můžete zlepšit zotavitelnost (recoverability) a oznamovat zjištěná fakta do plánování a údržby konfigurace.
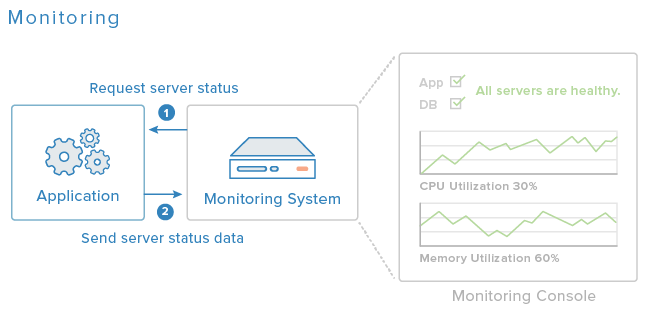
Ukázku monitorovacího systému vidíte na diagramu výše. Monitorovací server typicky požaduje stavová data od softwarového agenta, který běží na aplikačních a databázových serverech, a každý agent odpovídá informacemi o stavu softwaru a hardwaru. Administrátoři systému se pak mohou pomocí monitorovací konzoly dívat na úhrnný stav aplikace a v případě potřeby si vydolují podrobnější informace.
Co je třeba promyslet
- Které služby monitorovat. Služby a software, které se rozhodnete monitorovat. Přinejmenším byste měli monitorovat stav všech služeb, které musejí být v dobrém zdravotním stavu, aby aplikace mohla fungovat řádně.
- Které zdroje monitorovat. Zdroje, které se rozhodnete monitorovat. Mezi takové zdroje patří CPU, paměť, úložiště a využívání sítě, a také úhrnný stav serveru.
- Retence dat. Doba, po kterou budete uchovávat monitorovaná data, než je odstraníte. Ta, spolu s volbou položek, které jste se rozhodli monitorovat, ovlivňuje, kolik diskového prostoru bude monitorovací systém požadovat.
- Pravidla detekce potíží. Hranice a pravidla určující, zda je služba nebo zdroj v dobrém zdravotním stavu. Služba nebo server se mohou považovat za zdravé, pokud běží a obsluhují požadavky, zatímco zdroje, jako je například úložiště, mohou generovat upozornění, pokud se stupeň jejich využití pohybuje po určitou dobu na nějaké hranici.
- Notifikační pravidla. Hranice a pravidla určující, zda se má odeslat notifikace. I když jsou notifikace důležité, stejně důležité je i vyladit notifikační pravidla tak, abyste jich nedostávali příliš mnoho; když je doručená pošta plná upozornění a varování, často se pak takové notifikace ignorují, takže jsou marné, prakticky totéž, jako kdyby vůbec žádné notifikace nebyly.
5. Centralizované logování
Centralizované logování může podpírat serverové prostředí tím, že umožňuje, na jediném místě v rámci celého prostředí, snadno prohlížet a prohledávat logy, které se za normálních okolností ukládají lokálně na jednotlivých serverech. Kromě většího pohodlí, protože se nemusíte přihlašovat do jednotlivých serverů kvůli tomu, abyste si mohli přečíst logy, umožňuje centralizované logování také snadno identifikovat problémy, které zasahují více serverů, protože v konkrétním časovém rámci korelujete (dáte do vzájemného vztahu) jejich logy. Také garantuje větší flexibilitu, pokud jde o retenci logů, protože lokální logy se dají „vyložit“ z aplikačních serverů do nějakého centralizovaného logového serveru, který má své vlastní, nezávislé úložiště.
Požaduje se pro produkční prostředí? Ne, ale podobně jako monitorování může i centralizované logování poskytovat neocenitelný vhled do serverového prostředí, jak postupně narůstá jeho velikost i složitost. Kromě toho, že je pohodlnější než tradiční logování, umožňuje rychle a s větším přehledem zkontrolovat serverové logy.
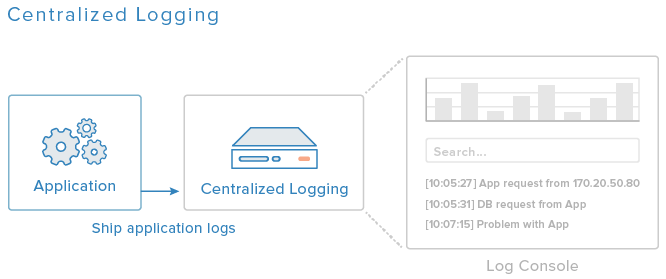
Diagram uvedený výše je zjednodušený příklad centralizovaného logovacího systému. Na každém serveru se nainstaluje nějaký agent zasílající logy a nakonfiguruje tak, aby odesílal důležité aplikační a databázové logy na centralizovaný logový server. Administrátoři systému pak mohou prohlížet, filtrovat a vyhledávat veškeré logy z jediné konzole.
Co je třeba promyslet
- Které logy shromažďovat. Konkrétní logy, které budete ze serverů odesílat do centralizovaného logového serveru. Měli byste shromažďovat důležité logy ze všech vašich serverů.
- Retence dat. Doba, po kterou budete uchovávat logy, než je odstraníte. Ta, spolu s volbou, které logy budete shromažďovat, ovlivňuje, kolik diskového prostoru bude centralizovaný logovací systém požadovat.
- Filtry logů. Filtry, které udělají rozbor původních logů, a převedou je na strukturovaná data. Filtrování logů zlepší vaše schopnosti, pokud je o dotazy na data, analýzy dat i jejich výstižné prezentace v grafech.
- Serverové hodiny. Zajistěte, aby byly hodiny všech serverů synchronizované a nastavené na stejné časové pásmo, aby byla časová osa logů v celém prostředí přesně stejná.
Závěr
Když dáte všechny probrané komponenty dohromady, mohlo by pak vaše produkční prostředí vypadat podobně jako tohle:
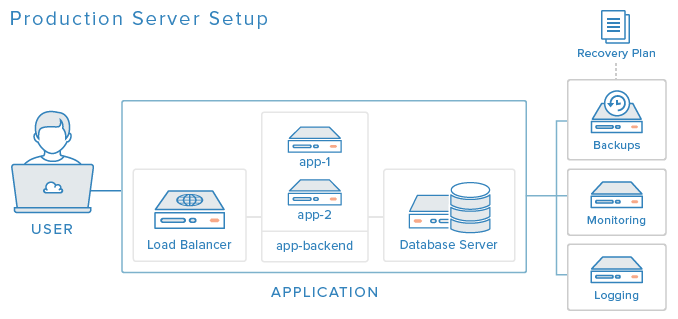
Nyní, poté, co jste se seznámili s komponentami, které mohou vylepšit konfiguraci produkčního serveru a být jejími oporami, měli byste začít uvažovat o tom, jak je integrovat do vašich serverových prostředí. Pochopitelně jsme nemohli probrat všechny možnosti, měli byste však být schopni udělat si představu, kde byste asi měli začít. Uvědomte si, že serverové prostředí byste měli navrhnout a implementovat tak, abyste dobře vybalancovali dostupné zdroje a cíle, které kladete na produkční prostředí.
![]() Článek byl přeložen díky ZonerCloud.cz – Výkonné servery s garancí 99,99% dostupnosti
Článek byl přeložen díky ZonerCloud.cz – Výkonné servery s garancí 99,99% dostupnosti
O autorovi
Napsal: Mitchell Anicas
Přeložil RNDr. Jan Pokorný
Znění původního článku najdete zde
![]()







Petr
Čvc 1, 2015 v 9:03Díky za zajímavé a dobré tipy. Logování je potřeba :)