Čeština v grafické knihovně GD




Určitě jste se setkali s tím, že se vám, při použití knihovny GD, nedařilo správně zobrazovat české znaky s diakritikou. A když už jste konečně přišli jak na to, zjistili jste, že s fonty TTF je vše úplně jinak? Dnes bych vám rád ukázal jak na to.
Grafická knihovna GD rozšiřuje PHP o možnost grafických výstupů. Výsledkem takového PHP skriptu může být i bitmapový obrázek. To se velice hodí například pro grafické znázornění nějakých dat. O tom, jak nakreslit graf pomocí PHP, si můžete přečíst v minulém článku. Nedělitelnou součástí nějakého grafu by měly být popisky os, legenda, případně ještě další doplňující informace. Nutně tedy potřebujeme do takového obrázku napsat i nějaký text. Pomocí funkce ImageString to jde velice snadno, jenže vše funguje správně pouze do té doby, dokud se v těchto textech nevyskytují české znaky s diakritikou. Konkrétně se jedná o znaky Ž, Š, Ť a ž, š, ť. Takové znaky ve výsledném obrázku prostě chybí. Je to způsobeno rozdílným kódováním ve zdrojovém textu vašeho PHP skriptu a kódováním knihovny GD.
Knihovna GD používá kódování ISO 8859/2 Latin 2. Uspořádání znaků v tomto kódování, tedy horní polovina kódové tabulky (znaky 128 – 255), vypadá takto:

Pokud své zdrojové texty skriptů PHP píšete ve windows, používáte nejspíše kódování Windows CP 1250. Uspořádání znaků v tomto kódování, tedy horní polovina kódové tabulky (znaky 128 – 255), vypadá takto:

Tato dvě kódování se samozřejmě liší. Co se českých znaků týká, rozdíl mezi nimi je právě ve výše zmíněných znacích Ž, Š, Ť a ž, š, ť, které, jak můžete vidět, leží v těchto tabulkách na různých místech.
Převod CP1250 na ISO 8859/2 Latin 2
Pro převod mězi těmito kódovými stránkami použijeme funkci StrTr.
|
Funkce StrTr má tři vstupní parametry, kterými jsou vstupní řetězec, tabulka znaků, které se mají ve vstupním řetězci nahradit, a tabulka znaků, kterými se nahrazované znaky mají nahradit. Výsledkem funkce je převedený textový řetězec. V našem případě je původní text uložen v proměnné $puvodni. Řetězec chr(138).chr(141).chr(142).chr(154).chr(157).chr(158) představuje našich šest znaků v kódování CP1250, které potřebujeme ve vstupním řetězci nahradit znaky v kódování ISO 8859/2 Latin 2. Znaky, kterými budeme nahrazovat, obsahuje poslední parametr, řetězec chr(169).chr(171).chr(174).chr(185).chr(187).chr(190). Zde ještě malá ukázka, jak tento převod použít v praxi.
|
Výsledek by měl vypadat takto:

Převodní řetězce můžeme zapsat i jinak, pomocí hexadecimálních kódů:
|
Domnívám se, že tento způsob by měl být rychlejší, protože převodní řetězce jsou předem dány, a při každém převodu se nemusejí opakovaně jednotlivé znaky sčítat.
Použití fontu TTF
Kromě základního fontu, kterým disponuje knihovna GD, máme možnost používat libovolné TrueType (TTF) fonty, musíme však kromě knihovny GD mít ještě knihovnu FreeType. To nám dává možnost použít ve svých obrázcích téměř libovolné písmo. Přináší to však další problém s kódováním českých znaků. TTF fonty jsou vytvořeny v kódování UTF8. A když si zkusíme vytisknout znaky 128 až 255, zjistíme, že většina českých znaků chybí. Ještě jednou se podívejte na horní polovinu tabulky CP 1250. Barevně jsou označeny české znaky, které v následující tabulce UTF8, v rozsahu od 128 do 255 úplně chybí. Nacházejí se totiž na místech s mnohem vyššími kódy. Jak se k nim dostat se dozvíte za malou chvilku.

A takhle vypadá tabulka UTF8 v rozsahu 128 – 255.
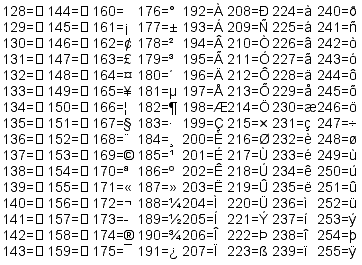
Převod CP1250 na UTF8
Když používáme v knihovně GD fonty TTF, místo funkce ImageString pro výstup textového řetězce musíme použít funkci ImageTTFText. Tato funkce má o tři parametry více.
|
Parametr $im je handle obrázku, $velikost_pisma určuje velikost písma v bodech, $uhel určuje úhel, pod kterým bude text vypsán. $x a $y jsou počáteční souřadnice umístění textu, $barva určuje barvu textu. Proměnná $soubor_fontu ukazuje cestu k souboru s TTF fontem. Nakonec proměnná $text obsahuje výstupní textový řetězec.
Do výstupního řetězce můžeme napsat prostý text, ale české znaky ve výstupním obrázku pochopitelně nebudou. Můžeme je však nahradit jejich UTF8 sekvencemi, které vypadají takto: &#xxx;, xxx představuje číselný kód znaku v tabulce UTF8.
Patřičné kódy českých znaků můžete nalézt na FTP serveru o UNICODE, nebo ve směrnici RFC 1345. Protože celá kódová tabulka UTF8 je příliš veliká, uvádím pouze vybrané české znaky.
|
Potřebujeme tedy ve výstupním řetězci nahradit české znaky patřičným UTF kódem. Na to nám funkce StrTr nestačí, neboť dokáže zaměňovat pouze jeden znak za jeden znak. Vyměnit jeden znak za řetězec znaků nezvládne. Musíme si na to napsat složitější funkci.
Využijeme výbornou vlastnost asociativních polí. V takovém poli totiž můžeme jednotlivým prvkům přiřadit jejich vlastní indexové hodnoty, což znamená, že pole nemusí obsahovat prvky 1 až 10, ale třeba jen 1, 5, 10, a to se nám hodí. My totiž potřebujeme 18 znaků z intervalu 0-255 nahradit jejich UTF8 kódy. Vytvoříme si tedy osmnáctiprvkové asociativní pole. Podívejte se, jak taková převodní funkce bude vypadat.
|
Ke komentářům v ukázce zdrojového kódu není co dodat. Pro doplnění ještě přikládám ukázku, jak převodní funkci PrevedNaUTF použít ve skriptu.
|
Výsledek by měl vypadat takto:

Převodní procedura PrevedNaUTF v tomto příkladu převádí z kódování Windows CP1250. Pokud potřebujete mít své zdrojové kódy v ISO 8859/2 Latin 2, stačí když přepíšete malé a velké š, ť a ž. Ostatní znaky mají stejné kódy, proto není potřeba dalších úprav.
A to je pro dnešek vše.
Starší komentáře ke článku
Pokud máte zájem o starší komentáře k tomuto článku, naleznete je zde.







Martin
Pro 15, 2015 v 6:22V tomhle byl vzdycky strasne bordel