Možnosti přístupu k datovým zdrojům 1.
Obsah
Související



Konečně se mi splnil můj velký sen. Ježíšek mi tento rok nachystal velké a radostné překvapení, pod stromečkem jsem nalezl vymodlenou a vytouženou SQL databázi. Ale jak se jen mám na ty data dostat? Co k tomu potřebuji? Že by další z danajských dárků? Pojďme se společně zamyslet, co všechno nám může přístup k datům usnadnit.
Kde jsou ty doby, kdy se slovní spojení – SQL databáze – vyskytovalo pouze při velkých korporacích nebo při teoretickém laškování se školnímí diagramy. S rozvojem internetu a obecnou popularizací výpočetní techniky se tento pojem již zcela zabydlel, a nejen to, praktickému využití již vůbec nic nebrání. Pomyslné dveře jsou otevřeny opravdu každému zájemci. Ruku v ruce s rozmachem různých datových strojů kráčí také rozvoj standardů a technologií, pomocí kterých si můžeme na data, zveřejněná pomocí sql db stroje, „stáhnout“. A právě s různými kombinacemi aktuálně užívaných technologií pro přístup k datům si zkusím pohrát v tomto článku.
Pestrá škála databázového vybavení na straně jedné a neméně široká paleta vývojářských produktů na straně opačné vytváří příliš široký prostor pro komplexní popis. Z tohoto důvodu se naše společné zamyšlení pokusím omezit na, podle mého názoru, nejpoužívanější a nejaktuálnější technologie. Existuje spousta zastaralých technologií, které lze samozřejmě použít, ale z nějakého důvodu byly inovovány či zcela nahrazeny mladším potomkem. Také existuje mnoho proprietárních řešení pro přístup k datům, ale u těchto způsobů nelze zaručit budoucí vývoj v podobě dostatečně silného garanta.
V tomto článku se nebudu zabývat praktickou realizací v různých programovacích jazycích, ale pokusím se popsat různé mezičlánky, které můžeme při své cestě za daty potkat. Nejprve si různé způsoby popíšeme v obecné rovině a následně si toto zobecnění zkonkretizujeme na platformu Windows za využití technologií firmy Microsoft a také jazyka PHP.
Význam použitých slovních spojení
- Datový stroj: samotná SQL databáze – aplikace+počítač (MySQL, Postgree…)
- Datový zdroj: data zpřístupněná pomocí datového stroje
- Databáze: struktura datového zdroje (tabulky, pole, relace, triggery…)
Obecný pohled
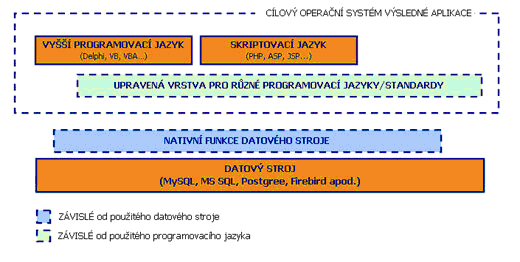
V této chvíli pomineme různost datovým strojů, operačních systémů a v neposlední řadě také programovacích jazyků. Soustřeďme se na obecnou rovinu problému co všechno potřebujeme na cestě za databázovými daty. Neujdeme skoro ani krok a už narazíme na takzvané nativní funkce datového stroje. Tohoto pomocníka nám připraví obvykle přímo tvůrci datového stroje pro zajištění základních komunikačních procesů. Tato vrstva pracuje na jedné z nejnižších úrovní a je obvykle součástí standardní instalace. Jediné, co už vás dělí od začátku databázové komunikace, je nastudování významu tímto způsobem zveřejněných API funkcí, takzvaný popis interface. Nutno přiznat, že právě toto je pro mnohé programátory dostatečným důvodem k další cestě za dokonalejšími pomocníky.
Na vyšší úrovni nás může potkat již specificky upravená vrstva. Může se jednat o vrstvu připravenou pro různé programovací jazyky takovým způsobem, abyste ji mohli zvoleným jazykem jednoduše uchopit a spolupracovat s ní (unity, moduly…). Nebo se může jednat o vrstvu vyhovující různým standardům, z důvodu možného uchopení větším množstvím programovacích jazyků (COM a podobně). Tato vrstva může mít také zobecňující charakter, tj. aplikace s ní komunikuje na obecné úrovni a jednoduchým nastavením lze měnit komunikaci vůči různým datovým strojům (ADOdb, ADO…).
Posledním, ale nejmocnějším článkem je zvolený programovací jazyk (PHP, Delphi…). Vše vsypeme do moždíře, přimáčkneme k vhodnému operačnímu systému, přidáme špetku vlastní kreativity a máme funkční databázovou aplikaci. Nyní budeme jen doufat, že se našim uživatelům neudělá špatně.
Kolem mně se všechno točí
Pro další pochopení článku je zcela lhostejné, který konkrétní databázový stroj zvolíme. Problematice různých databází se na Intervalu věnuje celá sekce, proto zamiřte tam.
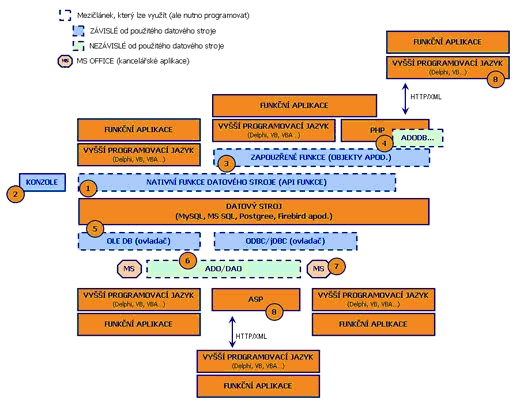
Nativní funkce (1, 2)
Jeden z prvních mezičlánků, na který můžeme narazit, jsou takzvané nativní funkce datového stroje. Pod tímto pojmem si představme sadu funkcí, kterou nám autoři datového stroje připravili pro komunikaci s jejich dítkem. Pod Windows se obvykle jedná o DLL knihovny, které si již v této fázi můžete přilinkovat do svého programovacího jazyka a pomocí nich začít komunikovat. Jde o naprosto stejný proces, jaký musíte podstupovat při přímém volání API funkcí Windows. Tento proces byl navržen primárně pro jazyky C, ale nyní jej již podporuje většina vyšších programovacích jazyků. V současné době bych tento přístup přirovnal spíše k menšímu masochismu, ale pravdou zůstává, že lze nalézt případy, kdy je tato varianta nutná z důvodu vysoké rychlosti.
Zastavil bych se ještě u takzvané konzole. U většiny datových strojů lze spustit příkazový terminál a pomocí textových příkazů komunikovat a získávat tak data. Tento mezičlánek lze s úspěchem použít při provádění akcí nad datovým strojem pomocí dávkových souborů, administraci, údržbě či přesunu většího množství dat mezi databázemi (dump). Opět lze zdůraznit vysokou rychlost provádění příkazů.
Zapouzdřené funkce (3)
Jak jsem již naznačil, volání nativních funkcí není příliš pohodlné, proto se programátoři uchylují k uschování těchto volání do obvyklých struktur daného programovacího jazyka. Například tím, že se vytvoří COM komponenta, moduly, unity, objekty a podobně (záleží na konkrétním programovacím jazyku). Programátor potom dle zaběhlých zvyklostí jazyka pracuje s touto komponentou a vůbec nebere v potaz nativní funkce, které se za ní skrývají. Často můžete narazit také na slůvko „wrapper“, které pojmenovává tento proces. Lze samozřejmě nalézt případ, kdy komponenta pracuje s databází přímo bez nativních funkcí, ale takový případ je opravdu ojedinělý a náročný na synchronizaci s vývojem databáze.
PHP (4)
A již jsme se dostali k vrstvě, na jejíž úrovni pracuje většině z nás známé PHP. Jelikož se PHP snaží podporovat většinu standardů (včetně COM), lze jej nalézt i v jiných vrstvách, ale pozice, kterou zde zmiňuji, je pro PHP typická.
PHP podporuje mnoho známých datových strojů, nevýhodou však je, že se jejich volání liší už na úrovni volání funkcí. Z tohoto důvodu se vytvořila sada jednotně pojmenovaných funkcí, které dle nastavení parametru datového stroje volají příslušné funkce od něj závislé. Aplikace, postavené na tomto řešení, jsou prakticky nezávislé na použitém datovém stroji. Daní za flexibilitu je možnost volání pouze zobecněných funkcí, které jsou kompatibilní napříč spektrem použitých datových strojů, a omezení použitého SQL na společný standard.
OLE DB, ODBC/jDBC (5)
Fakt, že výměna db stroje může znamenat nefunkčnost databázové aplikace, donutila softwarové společnosti k vývoji standardů, které se snaží přístup k datovým zdrojům zobecnit a zakrýt tak specifickou, na db stroji závislou komunikaci. Mezi etablované standardy se může řadit například systém ODBC ovladačů. Zpočátku si mnoho příznivců nezískal z důvodu nízké výkonnosti, ale postupným vývojem a odlaďováním ovladačů se stal standardem, akceptovaným i přes (mnohdy až fanatický) odpor některých programátorů. Microsoft však brzy narazil na své limity, proto vyvinul nový standard OLE DB. Jeden z přínosů OLE DB mezivrstvy spočívá v nezávislosti na sloupcovo-řádkové struktuře dat (může pracovat například nad strukturou adresářů a podobně). Jelikož OLE DB ovladač se stará také o interpretaci SQL dotazů, není jeho přímá tvorba zrovna jednoduchá, ale na druhou stranu není ani nemožná.
V současnosti se již užívá systém OLE DB ovladačů, ale z důvodu zpětné kompatability bývá standardně přítomen také ovladač OLE DB pro ODBC.
ADO (6)
Pod těmito třemi písmeny se skrývá technologie, kterou vyvinul Microsoft pro obecný přístup k datovým zdrojům pro programovací jazyky podporující COM technologii. S nástupem technologie .NET jste se mohli setkat také s ADO.NET. Nejedná se, jak by se mohlo zdát, o novou verzi této technologie, ale o paralelní vývojovou řadu. Mezi hlavní rozdíly patří bezpochyby soustředění ADO.NET na takzvaný „odpojený model“ (disconnected paradigm), kdy provedete dotaz, pomocí něj se naplní objekt recordset a ten se následně odpojí od datového zdroje. Po případných změnách nad tímto recordsetem se pak provede zpětná synchronizace. Popis technologie ADO by vydal spíše na celou knihu, proto se jí zde raději nebudu zabývat, abych nezpůsobil zbytečné zmatení.
MS Office (7)
Na stejné úrovni s technologií ADO můžeme nalézt také oblíbený kancelářský balík MS Office. Jistě znáte databázového člena tohoto balíku, aplikaci MS Access. Kdo s ní pracuje, získává automaticky přehled možností technologie ADO. Vlastní MS Access je ve své podstatě grafický interface, pomocí kterého komunikujeme s OLE DB ovladačem MS Jet, jehož nativní formát je známý *.MDB soubor. Z toho plyne, že se souborem *.MDB můžeme pracovat i bez aplikace MS Access, pouze za pomoci technologií ADO a OLE DB, což oceníme všude tam, kde si nevystačíme s jednoduchými kancelářskými operacemi.
Zde se nabízí ještě jedna možnost přístupu k db zdroji. Pomocí technologie COM kontaktovat aplikaci MS Office a pomocí ní se připojit k datovému zdroji. Ve většině případů jde o krkolomnou a velice neefektivní záležitost, ale při řešení problémů, obzvláště ve spojení s jazykem VBA, se může někdy hodit.
Speciální přístup k DB zdroji (8)
Tato možnost přístupu k datovým zdrojům je omezena pouze na přístupy z lokálního počítače (localhost), obvykle z důvodu vyšší bezpečnosti, například u „free webů“ a podobně. Můžeme si vytvořit PHP/ASP lokální skript pro spuštění libovolného SQL dotazu, který nám vrátí data například v XML formátu. (Pokud použijeme DTD uložených recordsetů z technologie ADO, získáme příjemně využitelnou kompatabilitu s ADO.)
Jak je vidět, přístup k datovým zdrojům je velice pestrou záležitostí s dynamickým vývojem. Pokud si nejste jisti, který ze způsobu přístupu využít, určitě nic nezkazíte, když se vydáte na internetové stránky výrobce db stroje, kde jistě naleznete informace o dostupných ovladačích. Článek samozřejmě nemohl obsáhnout všechny možné přístupy, doufám ale, že bude rozbuškou pro vaše vlastní neotřelé nápady (teoretické či již vyzkoušené v praxi), které můžete prezentovat v diskuzi. Příště si ukážeme různé možnosti administrace databází pomocí převážně grafických rozhraní.
Starší komentáře ke článku
Pokud máte zájem o starší komentáře k tomuto článku, naleznete je zde.