Úvod do JDBC
Obsah
Související




V tomto článku se budeme detailně věnovat jedné z technologií, která je základem J2EE a která je určena pro práci s databázemi, technologií JDBC, neboli Java Database Connectivity.
JDBC API poskytuje základní rozhraní pro unifikovaný přístup k databázím. Základem konceptu JDBC je využití funkčnosti poskytované JDBC ovladačem, který je následně překládá do nativních volání dané databáze. Díky tomu je aplikační programátor odstíněn od specifického API databáze a může se naučit jednotné rozhraní JDBC, které pak použije pro přístup do libovolné databáze, která poskytuje JDBC ovladač. V dnešní době to jsou prakticky všechny hlavní systémy a ovladače jsou optimalizované a vyvíjené samotnými výrobci databázových strojů.
JDBC navíc není určeno pouze pro přístup k relačním databázím, ale k libovolnému formátu dat, ukládaného ve „sloupcové podobě“, což mohou být i datové soubory „spreadsheetů“, textové soubory (např. CSF) atd.
Z pohledu historie bylo JDBC inspirováno ODBC standardem navrženým firmou Microsoft. ODBC jako takové bylo založené na X/Open CLI specifikaci a bylo primárně přístupné pouze přes C/C++ aplikace, případně přes různé „wrappery“ volání z různých vývojových prostředí (Visual Basic, Powerbuilder atd.). ODBC je tedy čisté C-čkové API, které nemá žádný objektový základ a je poměrně nepřehledné a nestrukturované. I proto firmy Microsoft v podstatě tuto technologii opustila a v .NET je přístup k datům a databázím řešen sofistikovaně a nabízí minimálně stejně tak dobré možnosti, jako JDBC.
Kromě jiného vývojáři v Javě mohou funkcionalitu ODBC snadno využívat, protože Sun Microsystems standardně nabízí ve svých JDK (Java Development Kit) vlastní JDBC ovladač určený pro přístup k ODBC. Původně byl tento ovladač vyvinut firmou Intersolve a dodáván samostatně, ale později došlo k jeho začlenění do JDK.
Architektura JDBC je poměrně přímočará a je zobrazena v následujícím diagramu:
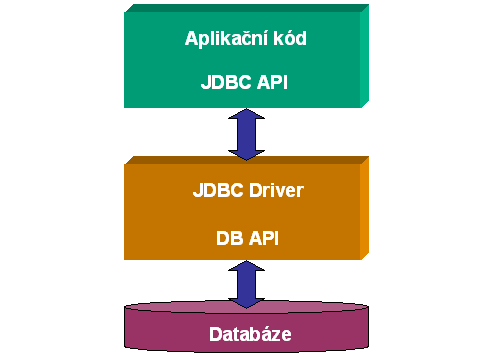
Přestože je schéma zjednodušené, naznačuje základní princip JDBC, jak jej vnímá aplikační programátor. Logika JDBC je ale složitější, v závislosti na vlastnostech JDBC ovladače.
Rozdělení JDBC
JDBC specifikace rozpoznává čtyři typy JDBC ovladačů, typ 1 až 4.
Typ 1
Tento typ ovladače využívá lokální ODBC ovladač a přistupuje k němu přes „JDBC-ODBC bridge“. Taková aplikace vyžaduje nainstalování a nastavení lokálního ODBC ovladače pro danou databázi společně s aplikací v Javě, která tento ODBC ovladač využívá.
ODBC ovladače jsou specifické pro každého výrobce databáze, a proto je práce s nimi složitá, je nutné instalovat lokální DLL knihovny, které musí být synchronizovány s ohledem na aktuální použitou databázi, jejich administrace je časově náročná díky nejednotnosti rozhraní, použití a nastavení atd. Z tohoto důvodu se aplikace využívající JDBC ovladač typ 1 hodí hlavně pro testování v prostředí Windows nebo na internetové/intranetové aplikace využívající JSP/Servlety. Jejich použití v čistě klientsky orientovaných aplikacích je komplikované právě díky náročnosti na konfiguraci na klientském počítači, hodí se spíše na serverově orientované aplikace, kde konfigurace nemusí být až takový problém.
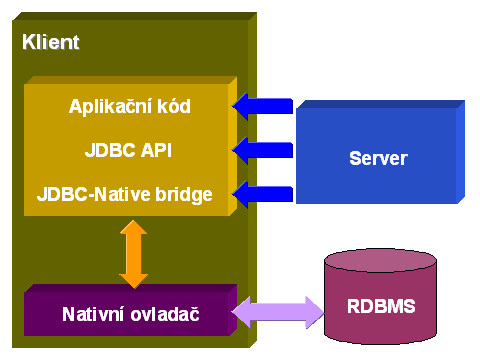
Typ 2
Ovladač typu 2 má za úkol překládat požadavky z JDBC do určitého specifického ovladače, který je v nativní podobě nainstalovaný na počítači a který je určen právě pro jeden typ databáze. Dalo by se říci, že „JDBC-ODBC bridge“ je podmnožinou tohoto typu ovladače, s tím, že je čistě vázán jen na ODBC. Pochopitelně se s tímto typem ovladačů pojí stejně výhod a nevýhod jako v případě JDBC-ODBC. Kromě toho ale mohou nastat ještě větší komplikace při administraci a při nasazení (opět záleží na umístění, zda se jedná o klienta nebo o serverový systém).
Typ 3
Tento typ již nepoužívá žádný nativní kód pro ovladač, ale je založen čistě na Javě a JDBC, které konvertuje svoji komunikaci do síťového protokolu, který se spojuje s centrálním serverem (Network Server), který poskytuje připojení k databázi (obvykle s „poolem“ připojení, viz dále). Tento server konvertuje síťový protokol, kterým komunikuje s klienty, do databázově specifického protokolu, jemuž již databáze rozumí. Takový model je vysoce efektivní, a to jak s ohledem na možnost „poolingu“ připojení a tím i zrychlení dotazování a práce s databází, tak i možnost připojení k sadě heterogenních databázových systémů.
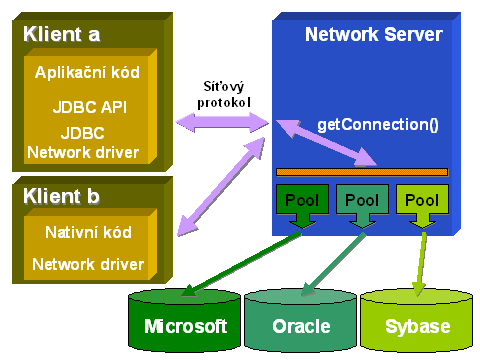
Architektura tohoto typu se obvykle používá v případě rozsáhlých systémů, kde z historických či „politických“ důvodů mohou být rozdílné databázové produkty a network server v podstatě nabízí unifikované rozhraní. Ten se pak pro aplikační programátory tváří jako jedna databáze a je nutné jej pouze jednou nastavit administrátorem takového serveru a následně provozovat.
Kromě toho, k network serveru se mohou připojovat i jiní než Java klienti, díky tomu, že síťový protokol je platformově nezávislý. Tato architektura tedy poskytuje nejen lepší možnosti k optimalizaci výkonu („pooling“), spojení heterogenních databází, ale i provázání heterogenních klientských platforem.
Typ 4
Ovladač typu 4 je napsán celý čistě v Javě s plnou podporou pro optimalizace vzhledem k dané databázi. Výhodou tohoto ovladače je, že klient nemusí být jakkoli konfigurován a nejsou nutné žádné lokální klientské instalace ovladačů.
Programátorský pohled
V předchozí části byla popsána architektura JDBC a možné způsoby, jak se připojovat k databázím. Následně bych se rád věnoval tomu, co potřebujete vědět, abyste mohli s JDBC pracovat, včetně uvedení jednoduchých příkladů.
JDBC ovladač
Základem JDBC je ovladač, jehož architektura byla popsána v předchozích kapitolách. Tento ovladač je specifická třída, obvykle poskytována výrobcem databáze. Předtím, než budou provedeny jakékoli operace nad databází, je nutné ovladač nahrát a registrovat. K tomu slouží příkaz Class.forName("jméno_JDBC_ovladače");. Příkladem může být „JDBC-ODBC bridge“, jehož ovladač se registruje (rozumějte, že se registruje pro použití ve vaší aplikaci) příkazem Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");.
Volání této statické metody musí být v try{} bloku, podobně jako ostatní operace nad databází. V tomto případě ale nebude vyvolána SQLException jako u metod pro práci s databází, ale vyvolá se ClassNotFoundException, což je výjimka informující, že systém nedokázal tuto třídu najít.
Registrace JDBC ovladače je vázána na DriverManager, což je třída s metodami pro správu a práci s JDBC. V podstatě jde o vrstvu mezi aplikačním kódem a JDBC ovladačem, přičemž v této vrstvě je provedena registrace JDBC ovladače ve chvíli, kdy je zavolána výše popsaná metoda forName(). Obecně by měl tento ovladač zavolat při nahrání metodu registerDriver() třídy DriverManager. Ten pak ovladač eviduje a je poskytnut pro práci s databází. To ovšem není pro aplikačního programátora důležité, protože se to děje bez jeho vědomí, jde o záležitost autorů JDBC ovladačů.
Spojení s databází
Jakmile byl JDBC ovladač nahrán a správně zaregistrován DriverManagerem, je možné navázat spojení s databází. Spojení s databází se identifikuje jako „databázové URL“, které se skládá z těchto součástí:
- URL musí být uvedeno „jdbc.“, což je určeno specifikací.
- Poté může být uveden podprotokol, což je záležitost závislá od daného poskytovatele databáze. Například pro ODBC je nutné uvést „odbc.“.
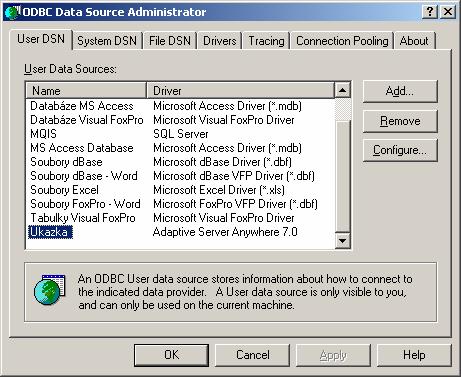
- Poslední částí pak je DSN (Data Source Name), který identifikuje název databáze (u ODBC to je název ODBC zdroje).
Bude-li v ODBC nastavení název zdroje „Ukazka“ (ukázkový zdroj pro Sybase SQL server), pak bude databázové URL vypadat následovně: jdbc.odbc.Ukazka.
Otázka definování URL je trošku složitější, budeme-li chtít využívat nějaký specifický port nebo se připojovat přes internet. I to je však jasně určeno specifikací, potřebné údaje se uvádějí jako součást DSN, a to ve formátu //host:port/dsn. Výrobce JDBC ovladače ale může specifikaci změnit, takže je vždy vhodné pořádně nastudovat dokumentaci k databázi, kterou používáte.
V zásadě URL jednoznačně identifikuje datový zdroj a lze s ním navázat spojení. K tomu slouží metoda getConnetion(), kterou je nutné zavolat u třídy DriverManager.
Jakmile se aplikační kód snaží navázat spojení s databází, DriverManager provádí základní testování ovladače (voláním metody connect, kterou musí ovladač implementovat, jako všechny ostatní z rozhraní java.sql.Driver) a předává URL jednotlivým registrovaným ovladačům, přičemž u prvního, který uspěje s připojením na dané URL, získá Connection objekt. Ten je pak následně předán volajícímu kódu.
Následující příklad uvádí, jak lze získat JDBC-ODBC připojení k databázi s URL, jež bylo uvedeno výše:
String url = “ jdbc.odbc.Ukazka“;
Connection con = DriverManager.getConnection(url, „dba“, „sql“ );
V případě, že jsme autorizovaní k získání připojení a vše je nastaveno správně, metoda getConnection() vrátí požadované spojení, které je základem pro další práci s databázi a přes které se provádí všechny operace nad databází.
Jakmile máme spojení s databází, můžeme nad ní začít provádět datové operace. K tomu je určena další třída, kterou nám poskytne vytvořený objekt Connection, tou je Statement (třída implementuje rozhraní java.sql.Statement popsané v dokumentaci JDK). Instance této třídy pak slouží pro posílání SQL příkazů databázi, kde jsou zpracovány a vrací odpovídající hodnoty. Statement nabízí velké množství metod (viz již zmíněná dokumentace), ale všemi se tu nebudeme zabývat. Nejdůležitější jsou pro začátek tyto metody:
- executeQuery()
- executeUpdate()
První metoda, executeQuery(), jak již její název napovídá, slouží k posílání dotazů (SELECT) do databáze, výsledkem jsou objekty třídy ResultSet (opět její metody určuje rozhraní java.sql.ResultSet, je vhodné se s nimi dobře seznámit z dokumentace). Výsledný „ResultSet“ již obsahuje skutečná data, která nás zajímají a s nimiž můžeme dál pracovat.
Druhá metoda, executeUpdate(), slouží k aktualizaci databáze a přijímá znakový řetězec podle standardu SQL92 pro aktualizaci, tedy příkazy jako UPDATE, INSERT, DELETE.
Použití vyplývá z následujícího příkladu:
try {
Class.forName(„sun.jdbc.odbc.JdbcOdbcDriver“);
String url = “ jdbc.odbc.Ukazka“;
Connection con = DriverManager.getConnection(url, „dba“, „sql“ );
Statement stmt = con.createStatement();
String sql = „SELECT * FROM KLIENTI“;
ResultSet set = stmt.executeQuery(sql);
} catch(Exception e) {}
Tento příklad demonstruje v zásadě všechny kroky nutné k tomu, aby se programátor dostal až k samotným datům a mohl s nimi pracovat. Pochopitelně by se dalo hovořit o dalších oblastech, jako je řízení transakcí, metadata atd., ale to by již bylo mimo rámec tohoto článku (tyto informace se přitom dají poměrně snadno najít v dokumentaci).
„Pooling“
Poslední, čemu bych se chtěl věnovat a co je podle mne důležité, je znalost „poolingu“. Jde o šikovnou funkčnost, kterou si programátor může napsat sám (viz níže přiložený kód) nebo může využít „pooling“ v rámci aplikačního serveru. Obě metody mají zásadní vliv na výkon systému, jejich optimalizací lze docílit řádového zvýšení rychlosti běhu aplikace. O co se tedy v „poolingu“ jedná?
Tento přístup se netýká jen databází, ale používá se i na jiné systémové zdroje a zefektivnění práce s nimi (jako jsou vlákna, určité univerzální objekty, bezstavové Session EJB a další). V případě databází se jedná o „poolování“ objektů Connection, neboli samotných připojení. Protože vytvoření samotného připojení je časově i systémově velmi náročná operace, která by při neustálém provádění při každém dotazu klienta znamenala nepřijatelné zpomalení aplikace, tyto objekty se předvytvářejí a ukládají se po použití zpět do „poolu“, odkud se zase berou podle potřeb klienta.
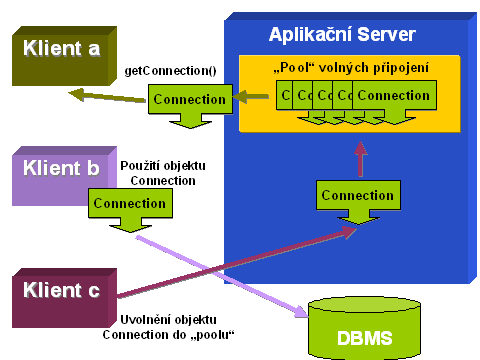
Práce s „poolingem“ je dosti aplikačně závislá a liší se podle výrobce aplikačního serveru. Na ukázku zde uvádím kód, který se používá pro dnes asi nejrozšířenější komerční J2EE server WebLogic:
Properties prop = new Properties();
// nastavení URL, je zde vidět, jak lze specifikovat
// DSN i s ohledem na protokol a jiný port
prop.put(„weblogic.t3.serverURL“, „t3://localhost:7001“);
// nastavení hesla, uživatele atd.
prop.put(„weblogic.t3.dbProps“, dbProps);
// identifikace poolu, je určena nastavení serveru v souboru weblogic.properties
prop.put(„weblogic.t3.connectionPoolID“, „myPool“);
Class.forName(„weblogic.jdbc.t3.Driver“).newInstance();
Connection con = DriverManager.getConnection(„jdbc.weblogic.t3“, prop);
Tento kód nám vrátí Connection objekt právě z „poolu“, který jsme si před spuštěním serveru nakonfigurovali (soubor weblogic.properties) a kde jsou spojení s databází předvytvořena. Jak je vidět, kód se příliš nezměnil, ale celková efektivita a rychlost běhu aplikace je nesrovnatelná se situací, kdy bychom spojení vytvářeli přímo sami a pokaždé zvlášť.
Na závěr bych chtěl uvést zdrojový kód pro klientský „pool“, který je touto třídou spravován a který nabízí základní „poolingovou“ funkčnost v rámci klientské aplikace. Není jej možné srovnávat s různými velkými systémy (ať již z OSS nebo komerčními), jeho význam je v testování, případně využití tohoto mechanismu pro menší aplikace.
Starší komentáře ke článku
Pokud máte zájem o starší komentáře k tomuto článku, naleznete je zde.








shadow
Čvn 23, 2010 v 21:12Hodně dobrý článek, dozvěděl jsem se velké množství hodnotných informací o JDBC.