Odstraňte bariéry svého webu – tabulky
Obsah
Související


Tabulky byly původně navrženy pro to samé, na co se používají na papíře. Spojení s internetem ale znamenalo jejich využití i při nutnosti přesného zobrazení prvků na webové stránce. Jak je ale nahradit nyní? Proč není dobré je používat a proč se staly bariérami?
Tabulky používané k rozvržení stránky aneb layout tables
Tabulky byly do HTML přidány jako prostředek ke strukturování tzv. tabulkových dat. Měly tedy na stránkách plnit stejnou funkci jako v běžném životě, např. prezentace ceníků, statistik nebo shrnutí. Poskytovaly na tu dobu úžasné formátovací možnosti, a proto se začaly využívat všude tam, kde bylo třeba dosáhnout přesného vzhledu, hlavně potom v oblasti celkového rozvržení stránky. Od tohoto způsobu využití tabulek je již dnes mohutně odrazováno, a to z několika důvodů (Zdůrazňuji, že tyto argumenty se týkají pouze tabulek používaných pro rozvržení stránky – tabulky jako prostředek pro strukturování tabulkových dat mají v moderních specifikacích svoje pevné místo a jsou pro tento účel jediným vhodným prvkem v (X)HTML.):
- Tabulky nedovolují stránku správně logicky strukturovat, pokud je používáte, musí obsah stránky následovat tak, jak se má zobrazit (od levého horního rohu do pravého dolního rohu). Kvůli tomu musí uživatelé používající nevizuální prohlížeče nejdříve projít méně důležitým obsahem stránky (respektive levým sloupcem prezentace) a až pak se dostanou k samotnému obsahu nebo v horším případě může dojít k úplné dezorientaci uživatele (co je na stránce vizuálně blízko sebe, nemusí být blízko sebe i ve zdrojovém kódu). Nevizuální prohlížeče čtou totiž stránku tak, jak je definována ve zdrojovém kódu. Oproti tomu stránky řešené pomocí CSS mohou být správně strukturované – nejdříve hlavní obsah stránky a až potom ostatní části (navigace, novinky..), související pasáže stránky se nacházejí ve zdrojovém kódu u sebe.
- Stránky rozvržené pomocí tabulek obsahují obrovské množství kódu, který tvoří pouze vzhled a nenese žádnou obsahovou informaci. Orientace v tomto kódu je pro nevizuální prohlížeče i vyhledávače značně problematická, navíc má stránka pouze díky tabulkám až o 50 % větší velikost.
- Stránku řešenou pomocí CSS zvádne interpretovat každý prohlížeč tak, aby jeho uživatel měl ze stránky maximální užitek (díky tomu že dokument je správně strukturován a nachází se v něm čistý obsah bez formátovacích tagů), což se o tabulkách rozhodně říct nedá.
Doufám, že jsem vás těmito argumenty donutil alespoň přemýšlet o plném nasazení CSS na vašich stránkách. Je sice pravda, že takovou stránku správně zobrazí pouze prohlížeče od pětkových verzí výše, ale myslím, že výhody, které z toho plynou (výborná přístupnost pro jakéhokoli uživatele s jakýmkoli prohlížečem a vyhledávačem, mnohem kratší a čistší zdrojový kód, mnohem méně práce ve chvíli nasazení pokročilejších technologií založených na XML), za to stojí.
Pokud se z nějakých důvodů přesto rozhodnete tabulky k výše zmíněným účelům použít, rozhodně byste v nich neměli používat tagy caption, th, thead, tfoot, colgroup a atributy axis, scope, headers a abbr. Naopak byste měli poskytnout popis účelu nebo funkce tabulky pomocí atributu summary tagu table (o všech zde zmíněných jevech si ještě povíme níže). Také byste se měli pokusit zachovat jakousi logickou strukturu informací ve zdrojovém kódu, tedy zajistit, aby zde na sebe informace alespoň navazovaly a jejich části nebyly různě rozházené.
Jak jsme právě popsali, tabulky používané k jiným účelům než k jakým byly původně určeny, jsou v oblasti přístupnosti pro handicapované uživatele poměrně značnou překážkou. Nyní se budeme věnovat klasickým tabulkám, kde je již situace mnohem lepší.
Tabulky používané ke strukturování tabulkových dat
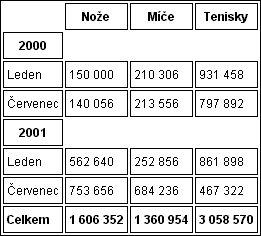
Vše si budeme ilustrovat na konkrétní tabulce, která zobrazuje zisky nějakého internetového obchodu:
|
Tato tabulka by v prohlížeči mohla vypadat nějak takhle (samozřejmě po přiřazení adekvátních vlastností pomocí CSS):
Všimněte si, že jsme správně použili tagy thead, tbody, tfoot k odlišení hlavičky, těla (tagů tbody se ale může v tabulce nacházet i více než jeden), patičky tabulky a th k vyznačení hlavičkových buněk tabulky (ty se mohou nacházet i mimo sekci thead). To není důležité jen z hlediska přístupnosti, ale i například při výstupu na tiskárně, kdy prohlížeč může nechat u delších tabulek vytisknout hlavičku a patičku na každé stránce. Pokud má navíc nějaká skupina sloupců v tabulce stejný význam a další skupina odlišný význam, měli byste je ve struktuře tabulky uvést jako příbuzné pomocí tagu colgroup.
Přesto má ale tato tabulka z hlediska přístupnosti zásadní nedostatky:
- Chybí jakýkoli popis nebo nadpis tabulky a uživatel s nevizuálním prohlížečem tak nemá šanci dozvědět se, jaký má tabulka význam ve stránce.
- Ve zdrojovém kódu je tabulka uvedena po řádcích, a proto ji každý nevizuální prohlížeč bude interpretovat po řádcích. V takovém případě je ale pro uživatele velmi obtížné neztratit orientaci v tabulce, protože tabulka mu bude interpretována takto:
Nože; Míče; Tenisky; 2000; 150 000; 210 306; 931 458 atd.
Toto samozřejmě vyplývá z podstaty tabulek, i tak je ale možné poměrně jednoduše dosáhnout toho, aby se uživatel s nevizuálním prohlížečem v tabulce neztratil.
Začneme prvním problémem z těch, které jsem nastínil, a sice informacemi o tabulce. Ty byste měli poskytovat pomocí následujících tří prostředků:
- Atribut
summarytagutable– zde byste měli vložit informace o účelu a struktuře tabulky. U tabulek sloužících k jinému účelu než strukturování tabulkových dat byste měli tento atribut uvést také a vysvětlit v něm úlohu tabulky ve stránce. - Tag
caption– tento tag musí být umístěn hned za tagemtablea jeho obsahem by měl být nadpis tabulky v jedné až třech větách. Tento text se objeví ve vizuálním prohlížeči nad obsahem tabulky. - Atribut
titletagutable– pokud nechcete uvádět nadpis tabulky pomocí tagucaption, můžete ho uvést i touto cestou. Tento text se ve vizuálním prohlížeči zobrazí většinou jako tooltip při nastavení kurzoru nad tabulku.
Tím bychom se vypořádali s prvním problémem. Nyní se podíváme na problém, jehož řešení již bude trochu komplikovanější – zajištění dobré orientace v tabulce i pro uživatele s nevizuálním prohlížečem.
Jak jsem již poznamenal, zařízení s jiným než vizuálním výstupem bude tabulku interpretovat po řádcích, tedy takto:
Nože; Míče; Tenisky; 2000; 150 000; 210 306; 931 458 atd.
Uživatel takového prohlížeče je tím pádem odkázán pouze na svou dobrou paměť, tedy na to, jak si zapamatuje jednotlivé hlavičky a pak je dokáže v duchu přiřazovat k jednotlivým hodnotám. To, jak sami uznáte, je velmi obtížné, a u větších tabulek snad i nemožné. A přitom by pouze stačilo přiřadit nějak obsahové buňky tabulky k příslušným hlavičkovým buňkám tabulky. A právě pro tento účel nabízí HTML od své čtvrté verze několik prostředků, které vám umožní asociovat obsahové buňky tabulky s hlavičkovými buňkami.
Začneme od nejjednoduššího z těchto prostředků, a tím je atribut scope tagu th. Může mít čtyři hodnoty, které si nyní popíšeme:
row– tagthobsahující atributscopes touto hodnotou je hlavičkovou buňkou pro všechny obsahové buňky ležící ve stejné řádce směrem vpravo od nějcol– tagthobsahující atributscopes touto hodnotou je hlavičkovou buňkou pro všechny obsahové buňky ležící ve stejném sloupci směrem dolů od nějrowgroup– tagthobsahující atributscopes touto hodnotou je hlavičkovou buňkou pro všechny obsahové buňky nacházející se ve stejné skupině řádků (ty jsou vymezeny tagythead,tbodyatfoot) a následující ve zdrojovém kódu za ním.colgroup– tagthobsahující atributscopes touto hodnotou je hlavičkovou buňkou pro všechny obsahové buňky nacházející se ve stejné skupině sloupců (ty jsou vymezeny tagycolgroup) a následující ve zdrojovém kódu za ním
Použití atributu scope je vhodné hlavně u jednodušších tabulek, u složitějších se ale již uplatňuje jiný prostředek, a to atribut headers tagu td ve spojení s atributem id tagu th.
Tento prostředek funguje v podstatě na tom principu, že pomocí atributu id pojmenujete jednotlivé hlavičkové buňky (tagy th) a potom pomocí atributu headers přiřazujete obsahovým buňkám (tagy td) všechna jména hlaviček (oddělená mezerami), které k buňce přísluší (u naší tabulky by například k buňce s obsahem 150 000 náležely hlavičkové buňky Leden, 2000 a Nože). Pokud to tak úplně nechápete, přesuňte se v článku trochu dál, kde se nachází upravená tabulka z prvního příkladu, v které používáme právě tuto metodu k zpřístupnění tabulkových dat.
Při použití právě zmíněných atributů bude nevizuální prohlížeč interpretovat naši tabulku takto:
Leden, 2000, Nože: 150 000; Leden, 2000, Míče: 210 306; Leden, 2000, Tenisky: 931 458 atd.
Někdy se dostaneme do situace, kdy jako obsah hlavičkové buňky musíme uvést delší text, abychom položku správně popsali. Tato situace by v naší tabulce mohla nastat, pokud bychom například místo položky Míče museli uvést Kopací míče – barevné. To je ale na škodu ve chvíli, kdy se má tento text neustále opakovat ve výstupu nevizuálního prohlížeče. Proto existuje atribut abbr tagu th, který můžete použít pro zkratku položky právě pro případ nevizuálního výstupu. S použitím tohoto atributu (přesněji s hodnotou Míče) bychom tedy dostali tento výstup:
Pro položku „Kopací míče – barevné“ bude použita zkratka „Míče“; Leden, 2000, Nože: 150 000; Leden, 2000, Míče: 210 306; Leden, 2000, Tenisky: 931 458 atd.
Další věc, kterou vám dnes představím, již patří spíše do budoucnosti, kdy bude internetem hýbat tzv. Sémantický web – tedy stránky, v nichž je pomocí XML definován význam jednotlivých slov a zpracování takových informací se pak stává téměř hračkou (to samozřejmě nadsazuji).
Tento způsob zpřístupnění tabulky ulehčí práci s ní všem uživatelům, tedy i handicapovaným. Zakládá se na tom, že si všechny hlavičkové buňky tabulky roztřídíme do skupin podle významu (hlavičkové buňky naší tabulky bychom tedy mohli roztřídit do skupin Zboží, Rok a Měsíc). Zařazení do příslušné skupiny deklarujeme pomocí atributu axis, jehož hodnotou je jméno skupiny. Pokud buňka náleží do více skupin, oddělujeme jednotlivá jména čárkou. Vedle toho musíme jednotlivým obahovým buňkám přiřadit hlavičkové buňky (pomocí výše popsaných způsobů).
Tímto způsobem bude ke každé obsahové buňce přiřazeno několik dvojic kategorie hlavičky:obsah hlavičky (počet závisí na tom, kolik k ní bude asociováno hlavičkových buněk pomocí parametru headers nebo scope). Tato skutečnost umožňuje obrovské možnosti zpracování dat v tabulce. Pokud zůstaneme v realitě webového prohlížeče, mohla by práce s naší tabulkou probíhat následovně:
Uživatel: Chci znát výši zisku v lednu 2000, pouze v kategorii Nože a Míče.
Prohlížeč: (pro sebe) Musím najít obsahové buňky, které mají přiřazeny hlavičkové buňky Měsíc:Leden, Rok:2000, Zboží:Nože nebo Měsíc:Leden, Rok:2000, Zboží:Míče a sečíst jejich obsah.
Prohlížeč: Výše zisku v lednu 2000, pouze v kategorii Nože a Míče, byla 360 306.
Interpretace „inteligentních tabulek“ ve webových prohlížečích ale není tou hlavní oblastí, kde by se tento jev dal uplatnit. Jejich hlavní využití vidím ve strojovém zpracovávání údajů z tabulky různými indexovacími stroji apod.
Pokud se vám „inteligentní tabulky“ zdají být již příliš náročné a zbytečné, můžete jejich princip, podle mého názoru, s klidem zapomenout. K dobrému zpřístupnění tabulek pro handicapované uživatele stačí důsledně používat tagy caption, thead, tbody, tfoot, th, colgroup, atributy headers, scope, abbr tagů th a td a také atribut summary tagu table.
Další alternativou je uvést v blízkosti tabulky odkaz na stránku, která kompletně popisuje tabulku takovým způsobem, jak jsem ukázal u výstupu nevizuálního prohlížeče při správně zpřístupněné tabulce.
Nyní si shrneme naše poznatky o zpřístupňování tabulek pro handicapované uživatele v následujícím příkladu, kde jsme upravili tabulku z našeho úvodního příkladu tak, aby byla plně přístupná handicapovaným uživatelům:
Příště se budeme zabývat moderními webovými technologiemi.
Starší komentáře ke článku
Pokud máte zájem o starší komentáře k tomuto článku, naleznete je zde.