Ukládání vícejazyčných záznamů s MySQL



Mějme tabulku výrobků v MySQL, do které chceme uložit název, cenu a popis výrobku spolu s identifikátorem skupiny, do které patří. Problém je ten, že PHP aplikace využívající tuto tabulku je vícejazyčná, takže název a popis výrobku musí být k dispozici ve více jazycích.
Nad touto tabulkou budeme chtít provádět následující operace:
- Vypsat výrobky z dané skupiny setříděné podle názvu, samozřejmě s dodržením pravidel třídění jednotlivých jazyků.
- Fulltextově vyhledávat v názvu a popisu.
- Musíme počítat se situací, že ne všechny texty budou vždy přeložené do všech jazyků.
- Čas od času budeme chtít přidat další jazyk.
Všechny dotazy, které budou s tabulkou pracovat, by měly být pokud možno jednoduché a hlavně by se měly vykonávat efektivně. To především znamená, že budou využívat indexy, protože např. vyhodnocení klauzule ORDER BY nazev LIMIT 10 s indexem zabere 10 operací, ale bez něj plných N * log N, kde N je celkový počet záznamů ve výsledku dotazu.
Překlady v samostatné tabulce
K řešení problému se dá přistoupit několika způsoby. První možnost je vyčlenit název a popis výrobku do samostatné tabulky a přidat identifikátor jazyka. Tento návrh má především tu výhodu, že se snadno přidávají další jazyky, a na první pohled vypadá čistě. Skutečnost je ale taková, že návrh směšuje data různého typu do jednoho sloupce – název sice může být ve všech jazycích např. varchar(50), pokaždé ale používá jiný způsob porovnávání (a případně i kódování). Kvůli tomu se data nedají efektivně třídit správně ve všech jazycích. Rozdělení dat do dvou tabulek navíc znemožňuje použití indexu pro setřídění záznamů vybraných z dané skupiny.
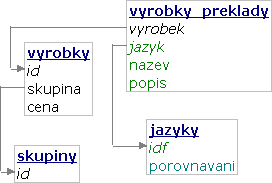
S efektivitou jsme na tom tedy špatně a o jednoduchosti dotazů se také nedá hovořit, obzvlášť pokud zohledníme, že všechny překlady nemusí být k dispozici. Neexistující překlady je přirozené do tabulky vůbec neukládat nebo pokud je k dispozici např. jen název, tak na místo popisu uložit NULL. Místo nich můžeme použít např. anglickou jazykovou verzi, která bude k dispozici vždy. Jednoduchý dotaz pro výpis výrobků z dané skupiny setříděný podle názvu se potom promění v následující monstrum:
„SELECT vyrobky.id, IFNULL(vyrobky_preklady.nazev, vyrobky_en.nazev) AS nazev, IFNULL(vyrobky_preklady.popis, vyrobky_en.popis) AS popis, vyrobky.cena
FROM vyrobky
LEFT JOIN vyrobky_preklady ON vyrobky.id = vyrobky_preklady.vyrobek AND vyrobky_preklady.jazyk = ‚$jazyk‘
INNER JOIN vyrobky_preklady vyrobky_en ON vyrobky.id = vyrobky_en.vyrobek AND vyrobky_en.jazyk = ‚en‘
WHERE vyrobky.skupina = $skupina
ORDER BY IFNULL(vyrobky_preklady.nazev, vyrobky_en.nazev) COLLATE $porovnavani“
Způsob porovnávání pro uživatelem zvolený jazyk si předem vybereme z tabulky jazyky a uložíme do proměnné $porovnavani.
Poslední problém je s fulltextovým vyhledáváním – MySQL při něm ignoruje slova, která jsou obsažena alespoň v polovině řádek (např. spojky a předložky). Tím, že jsou všechny jazyky smíchané dohromady, k tomu prakticky nedojde a zbytečně se budou prohledávat i tato slova. Kromě toho není možné kombinovat fulltextový index s obyčejným, takže v klauzuli WHERE jazyk = 'en' AND MATCH (nadpis, popis) AGAINST ('dotaz') se nebude moci použít index nad sloupcem jazyk.
Kopie dat
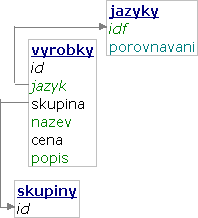
Záznamy můžeme mít v tabulce zkopírované do jednotlivých jazyků včetně jazykově nezávislých sloupců. Dá se to automaticky zařídit např. triggerem, ale i tak zůstane nevýhoda duplicitního uložení dat. Z problémů předchozího řešení zůstane nemožnost efektivního třídění se zohledněním rozdílů mezi jazyky a neefiktivita fulltextového vyhledávání. Navíc se zkomplikuje přidání dalšího jazyka – kromě uložení do tabulky jazyků musíme rozkopírovat všechna data v jazykově citlivých tabulkách nebo všechny dotazy zkomplikovat nouzovým použitím anglické verze:
„SELECT vyrobky_en.id, IFNULL(vyrobky.nazev, vyrobky_en.nazev) AS nazev, IFNULL(vyrobky.popis, vyrobky_en.popis) AS popis, vyrobky.cena
FROM vyrobky vyrobky_en
LEFT JOIN vyrobky ON vyrobky_en.id = vyrobky.id AND vyrobky.jazyk = ‚$jazyk‘
WHERE vyrobky_en.jazyk = ‚en‘ AND vyrobky_en.skupina = $skupina
ORDER BY IFNULL(vyrobky.nazev, vyrobky_en.nazev) COLLATE $porovnavani“
Překlad přímo v tabulce s daty
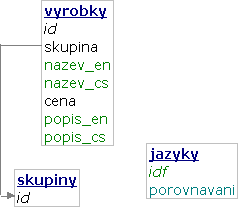
Další možností je připravit v tabulce pro každou přeložitelnou hodnotu tolik sloupců, kolik máme jazyků. Z návrhu je patrné, že přidání jazyka nebude právě jednoduché a bude při něm potřeba změnit strukturu tabulek. Nicméně pokud se s tím smíříme, získáme systém, ve kterém se dotazy pokládají elegantně a vyhodnocují efektivně. Např. dotaz pro výpis výrobků z dané skupiny je v podstatě stejně jednoduchý jako bez jazykových verzí:
„SELECT id, nazev_$jazyk, popis_$jazyk, cena
FROM vyrobky
WHERE skupina = $skupina
ORDER BY nazev_$jazyk“
Tento dotaz je nejen elegantní, ale také efektivní – při správném nastavení způsobu porovnávání přímo v definici tabulky a existenci indexu (skupina, nazev_$jazyk) databáze provede vše stejně rychle jako v jednojazykové verzi. Totéž platí pro fulltextové vyhledávání.
Nepřeložené texty je vhodné řešit zkopírováním výchozí jazykové verze, protože použití hodnoty NULL by dotazy zkomplikovalo a zneefektivnilo. Navíc by s hodnotou NULL neplnily svou roli unikátní indexy (příkladem překládaných dat, nad kterými by měl existovat unikátní index, je URL výrobku). Pokud bychom potřebovali evidovat seznam nepřeložených dat (aby překladatelé věděli, co mají překládat), je vhodné ho udržovat v samostatné tabulce.
Zbývá vyřešit problém, jakým lze do existující struktury přidat nový jazyk. Postarat se o to může samozřejmě skript:
<?php
/** Přidání jazykových sloupců do všech tabulek
* @param string $lang identifikátor jazyka
* @param string [$collation] způsob řazení textů
* @return null provedení příkazů ALTER TABLE a UPDATE
* @copyright Jakub Vrána, http://php.vrana.cz
*/
function add_language($lang, $collation = „“) {
$result = mysql_query(„SHOW TABLES“);
while ($row = mysql_fetch_row($result)) {
// přidání a zkopírování sloupců
$alter = array();
$update = array();
$result1 = mysql_query(„SHOW COLUMNS FROM $row[0]“);
while ($row1 = mysql_fetch_assoc($result1)) {
if (substr($row1[„Field“], -3) == „_en“) {
$field = substr($row1[„Field“], 0, -2) . $lang;
$null = ($row1[„Null“] == „NO“ ? “ NOT NULL“ : „“);
$alter[] = „ADD $field $row1[Type]“ . ($collation ? “ COLLATE $collation“ : „“) . „$null AFTER $row1[Field]“;
$update[] = „$field = $row1[Field]“;
}
}
mysql_free_result($result1);
if ($alter) {
mysql_query(„ALTER TABLE $row[0] “ . implode(„, „, $alter));
mysql_query(„UPDATE $row[0] SET “ . implode(„, „, $update));
// přidání indexů
$indexes = array();
$result1 = mysql_query(„SHOW INDEXES FROM $row[0]“);
while ($row1 = mysql_fetch_assoc($result1)) {
$type = ($row1[„Index_type“] == „FULLTEXT“ ? „FULLTEXT“ : ($row1[„Non_unique“] ? „INDEX“ : „UNIQUE“));
$indexes[$type][$row1[„Key_name“]] .= „$row1[Column_name], „;
}
mysql_free_result($result1);
foreach ($indexes as $type => $type_indexes) {
foreach ($type_indexes as $index) {
if (preg_match(‚~_en, ~‘, $index)) {
mysql_query(„ALTER TABLE $row[0] ADD $type (“ . substr(preg_replace(‚~_en, ~‘, „_$lang, „, $index), 0, -2) . „)“);
}
}
}
}
}
mysql_free_result($result);
}
?>
Skript se automaticky postará o vytvoření nových sloupců, zkopírování nepřeložených dat a přidání indexů. Jeho slabinou je potřeba oprávnění ALTER.
Závěr
Leckdo se domnívá, že na první pohled čistá struktura jazykových dat je pro aplikaci ta správná. Bohužel je to pouze teorie, protože v praxi je mnohem důležitější, aby se dotazy snadno pokládaly a rychle vyhodnocovaly a aby správně fungovalo řazení dat i fulltextové vyhledávání. To vše je samozřejmě mnohem důležitější než potřeba snadného přidání nového jazyka, ke kterému za dobu životnosti aplikace dojde obvykle jen párkrát. Při bližším ohledání se navíc ukazuje, že ani s tou čistotou návrhu to není tak slavné, protože se data různého datového typu ukládají do stejného sloupce.
Podrobnější anglická verze tohoto článku vyšla v časopise php|architect – duben 2009.







