



Jednasedmdesát procent současných internetových uživatelů nemá jako svůj mateřský jazyk angličtinu, a tento procentový podíl stále stoupá. Na internalizaci se přitom specializuje jen málo lidí. Důsledkem je, že se s ní většina webů vypořádává špatně — protože věci, které na první pohled vypadají jednoduše, ve skutečnosti často takové vůbec nejsou.
Vezměme pluralizaci, tedy převod do množného čísla. Snaha měnit v řetězcích slova uvedená v jednotném čísle do množného čísla rychle selže — dokonce už i v angličtině, kde většina slov v množném čísle končí na s. Pracoval jsem například na jedné aplikaci pro sdílení fotek, která podporovala dvě řeči, angličtinu a čínštinu. Bylo snadné přidat písmeno s do zobrazovaných textů, jako jsou “X like[s]” či “Y comment[s]”. Co když ale budu potřebovat převést do množného čísla slova, která je tvoří nepravidelně, jako “foot”, “inch” nebo “quiz”? Už zde se náš pokus o jednoduché řešení zhroutí, byla to jen nepovedená nouzovka.
Přitom angličtina přestavuje poměrně snadný případ. Mnohé jazyky mají víc než dva tvary množného čísla: arabština jich má například šest a mnohé slovanské jazyky více než tři. Skutečně, přinejmenším 39 jazyků má více než dva tvary množného čísla. Naopak některé jazyky vůbec množné číslo nemají, patří mezi ně čínština a japonština, což znamená, že tvar podstatných jmen v jednotném a množném čísle je stejný.
Jak zvládnout záludnosti množného čísla — a vyřešit je v projektech řádně? V tomto článku předvedu některé z nejběžnějších potíží spojených s převodem do množného čísla a vysvětlím, jak se s nimi vypořádat.
Potíže spojené s převodem do množného čísla
Převod do množného čísla je ještě složitější, než jsem zatím uvedl: každý jazyk má vlastní pravidla pro definice jednotlivých tvarů množného čísla. Pravidlo pro množné číslo definuje tvar množného čísla pomocí vzorce, který zahrnuje nějaký čítač. Tento čítač vyjadřuje počet položek, který se snažíte převést do množného čísla. Řekněme, že pracujeme s řetězcem “2 rabbits” (2 králíci). Číslovka před slovem “rabbits” je ten čítač. V tomto případě má hodnotu 2. Pokud jako ukázku vezmeme angličtinu, ta má dva tvary: singulár a plurál. Pravidlo proto bude vypadat takto:
- Pokud má čítač celočíselnou hodnotu 1, použijte tvar pro jednotné číslo (singulár): “rabbit”.
- Pokud má čítač hodnotu,která není rovna jedné, použijte tvar pro množné číslo (plurál): “rabbits”.
To však neplatí třeba pro polštinu, v ní to neplatí, protože totéž slovo —“rabbit” neboli “królik” — může nabývat více než dvou tvarů:
- Pokud má čítač celočíselnou hodnotu 1, použijte “królik”.
- Pokud má čítač hodnotu, která končí na 2–4, vyjma 12–14, použijte “królika”. [1]
- Pokud čítač není 1 a má hodnotu, která končí buď na 0, nebo na 1, nebo čítač končí na 5–9, nebo čítač končí na 12–14, použijte “królików”.
- Pokud má čítač jakoukoli jinou hodnotu, než jsou ty uvedené výše, použijte “króliki”.
Tolik k “singuláru” a “plurálu”. Pro jazyky, které mají tři nebo více tvarů pro množné číslo, potřebujete specifičtější jmenovky.
Různé jazyky používají různé číslice
Možná chcete s podstatným jménem v množném čísle také zobrazit čítač, jako v “You have 3 rabbits”. Některé jazyky však nepoužívají arabské číslice, na které jste zvyklí — Arabové například používají indo-arabské číslice, ٠١٢٣٤٥٦٧٨٩:
- 0 knih: كتاب ٠
- 1 kniha: كتاب
- 3 knihy: كتب ٣
- 11 knih: كتابًا ١١
- 100 knih: كتاب ١٠٠
Různé jazyky nebo regióny používají různé číselné formáty
Často se také snažíme přispět k tomu, aby se snadněji četla velká (dlouhá) čísla, proto do nich přidáváme oddělovače. V anglosaském prostředí zapisujeme číslo 1000 ve tvaru“1,000”. Mnohé jazyky a regióny však používají jiné oddělovače desetinných míst a tisíců. Němci například zapisují číslo 1000 ve tvaru “1.000.” Některé jazyky neseskupují velká čísla podle tisíců, ale podle desetitisíců.
Řešení: MessageFormat ICU
Vyřešit dobře převod do množného čísla je složitá úloha — při nejmenším, pokud chcete zpracovat všechny mezní případy a výjimky. Nedávno udělala organizace ICU (International Components for Unicode) přesně tohle s MessageFormat. MessageFormat ICU je značkovací jazyk specificky šitý na míru lokalizaci. Umožňuje definovat, deklarativním způsobem, jak se mají podstatná jména realizovat v rozličných tvarech množného čísla. Roztřídí všechny tvary a pravidla pro množné číslo a správně formátuje čísla. Mnozí z vás bohužel o MessageFormat ještě vůbec nic nevědí, protože ho většinou používají jen lidé, kteří se zabývají internacionalizací — zasvěceným je znám pod numeronymem i18n — a JavaScript se teprve nedávno rozvinul tak, aby ho dokázal zpracovat.
Povězme si, jak pracuje.
Používání CLDR pro tvary množného čísla
CLDR je zkratka Common Locale Data Repository (společný repozitář lokálních dat), z něhož firmy jako Google, IBM a Apple vytahují informace o formátování čísel, data a času. CLDR dále obsahuje data o tvarech a pravidlech pro množné číslo mnoha jazyků. Pravděpodobně je to světově nejrozsáhlejší repozitář lokálních dat, což z něho činí ideální základnu pro jakýkoli internacionalizační JavaScriptový nástroj.
CLDR definuje až šest různých tvarů množného čísla [2]. Každý tvar má přiřazený název: zero, one, two, few, many nebo other (žádný, jeden, dva, málo, mnoho, ostatní). Mnohé lokály nepotřebují úplně všechny tvary; vzpomeňte si, že angličtina má jen dva: jeden a ostatní. Název každého tvaru je založený na odpovídajícím pravidlu pro množné číslo. Podívejte se na ukázku CLDR pro polštinu — mírně pozměněná verze našich předchozích pravidel pro čítač:
- Pokud má čítač celočíselnou hodnotu 1, použijte tvar s názvem one.
- Pokud má čítač hodnotu, která končí na 2–4, vyjma 12–14, použijte tvar s názvem few.
- Pokud čítač není 1 a má hodnotu, která končí buď na 0, nebo na 1, nebo čítač končí na 5–9, nebo čítač končí na 12–14, použijte tvar s názvem many.
- Pokud má čítač jakoukoli jinou hodnotu, než jsou ty uvedené výše, použijte tvar s názvem other.
Není nutné implementovat tvary množného čísla CLDR ručně, můžete k tomu využít vhodné nástroje a knihovny. Já jsem například vytvořil L10ns, který kompiluje kód za vás; FormatJS, sada JavaScriptových knihoven od Yahoo, má vestavěné všechny tvary množného čísla. Obrovským benefitem těchto nástrojů a knihoven je, že dobře škálují, když přebírají zpracování tvarů množného čísla. Pokud byste se rozhodli, že budete tvary množného čísla kódovat „natvrdo“ explicitně sami, vyčerpáte nejen sami sebe, ale i všechny spolupracovníky týmu, protože budete muset mít neustále přehled o všech tvarech a pravidlech a definovat je znovu a znovu, a to vždy a všude, jakmile budete chtít naformátovat nějaký řetězec do množného čísla.
MessageFormat
MessageFormat je doménově specifický značkovací jazyk, který využívá CLDR, a je konkrétně ušitý na míru lokalizaci řetězců. Značkování definujete inline. Chceme například naformátovat zprávu “I have X rabbit[s]” pomocí správného tvaru množného čísla pro slovo “rabbit”:
var message = ‚I have {rabbits, plural, one{# rabbit} other{# rabbits}}‘;
Jak vidíte, definuje se formát množného čísla uvnitř složených závorek {}. Přebírá jako svůj první argument čítač, rabbits. Druhý argument určuje typ formátování. Třetí argument uvádí tvar množného čísla CLDR (one, many). Uvnitř složených závorek je třeba nadefinovat vnořenou zprávu, která odpovídá jednotlivým tvarům množného čísla. Můžete také předat symbol #, aby se realizoval i čítač v patřičném číselném formátu a číselném systému, takže se tím řeší i výše zmíněné problémy s indo-arabským číselným systémem a formátováním čísel.
Zde provádíme rozklad zprávy v lokálním prostředí en-US a na výstupu uvádíme různé zprávy závisející na tom, který tvar množného čísla přebírá proměnná rabbits:
var message = 'I have {rabbits, plural, one{# rabbit} other{# rabbits}}.';
var messageFormat = new MessageFormat('en-US');
var output = messageFormat.parse(message);
// Vypíše „I have 1 rabbit.“
console.log(output({ rabbits: 1 }));
// Vypíše „I have 10 rabbits.“
console.log(output({ rabbits: 10 }));
Benefity plynoucí z inline definic
Jak jste viděli v předchozí zprávě, definovali jsme formát množného čísla inline. Pokud bychom to nedělali inline, museli bychom opakovat slova “I have…” pro všechny tvary množného čísla, zatímco zde stačilo je napsat jen jednou. No a představte si, že byste museli opakovat mnohem víc slov, jako v následující ukázce:
{
one: 'My name is Emily and I got 1 like in my latest post.'
other: 'My name is Emily and I got # likes in my latest post.'
}
Kdybychom nedefinovali formát inline, museli bychom pokaždé opakovat “My name is Emily and I got…in my latest post” (Jmenuji se Emily a dostala jsem … ve svém nejnovějším příspěvku). To je spousta slov.
MessageFormat ICU naproti tomu věci zjednodušuje. Nemusíme pro každý tvar množného čísla opakovat stejnou frázi, stačí lokalizovat slovo “like” (tedy kolik dostala Emily „lajků“):
var message = ‚My name is Emily and I got {likes, plural, one{# like} other{# likes}} in my latest post‘;
Zde nemusíme opakovat slova “My name is Emily and I got…in my latest post” pro každý tvar množného čísla. Stačí prostě jen lokalizovat slovo “like”.
Benefity plynoucí z vnořování zpráv
Vnořovaná povaha MessageFormat také vypomáhá tím, že nabízí nekonečné možnosti, jak definovat celé zástupy složitých řetězců. Abychom předvedli, jak flexibilní MessageFormat je, nadefinujeme zde výběrový formát ve formátu množného čísla:
var message = '{likeRange, select,\
range1{I got no likes}\
range2{I got {likes, plural, one{# like} other{# likes}}}\
other{I got too many likes}\
}';
Výběrový formát se skládá ze sady případů a podle toho, který případ právě nastal, se vypíše odpovídající vnořená zpráva. Je bezvadné, že můžeme sestrojovat zprávy založené na rozsazích. V předchozí ukázce sestrojujeme tři druhy zpráv pro jednotlivé rozsahy like. Jak vidíte v range2, definovali jsme formát množného čísla tak, aby naformátoval zprávu “I got X like[s],” a dovnitř výběrového formátu jsme vnořili formát množného čísla. Tento příklad ukazuje velmi složité formátování, jehož je schopno docílit jen velmi málo syntaxí, a předvádí, jak flexibilní je MessageFormat.
S formátem uvedeným výše získáte podle dané situace jednu z těchto zpráv:
- “I got no likes,” pokud je likeRange uvnitř range1.
- “I got 1 like,” pokud je likeRange uvnitř range2 a počet lajků je 1.
- “I got 10 likes,” pokud je likeRange uvnitř range2 a počet lajků je 10.
- “I got too many likes,” pokud likeRange není ani uvnitř range1, ani uvnitř range2.
To jsou velmi drsné požadavky na lokalizaci — nedokáže to ani jeden z nejoblíbenějších internacionalizačních nástrojů, gettext.
Úložiště a předkompilované zprávy
Nemusíte však nutně ukládat zprávy MessageFormat v proměnné JavaScriptu, možná raději sáhnete po nějakém jiném druhu úložného formátu, například několik souborů JSON. To umožní zprávy předkompilovat do jednoduchých lokalizačních getterů. Pokud to nechcete zpracovávat sami, zkuste L10ns, který zařídí úložiště a předkompilaci za vás, a také synchronizuje překladové klíče mezi zdrojem a úložištěm.
Měli by překladatelé znát MessageFormat?
Možná si myslíte, že by bylo přehnané a příliš zatěžující požadovat od neprogramujících překladatelů, aby znali MessageFormat a tvary plurálu CLDR. Podle mých zkušeností se vyplatí naučit je základy značkování, jak vypadá a co dělá, a jaké tvary plurálu má CLDR. Zabere vám to jen pár minut, ale překladatelům tím dodáte postačující informace, aby mohli při své práci využívat MessageFormat. Navíc, aby bylo webové rozhraní L10ns snadněji pochopitelné, zobrazuje pro každý tvar plurálu CLDR konkrétní příklady čísel.
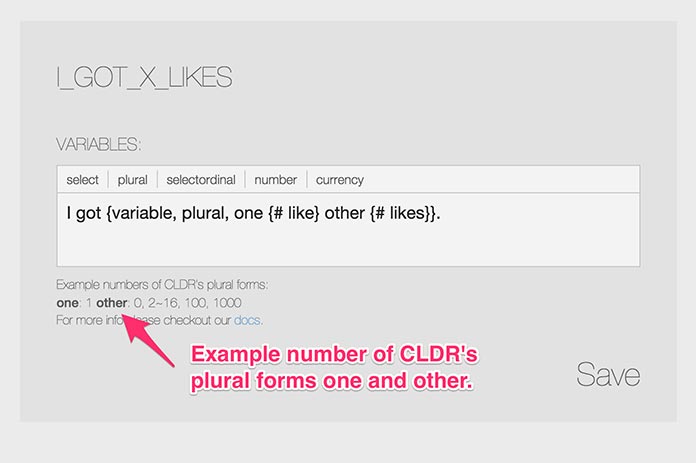
Překlad červeného nápisu na obrázku:
Konkrétní příklady čísel pro tvary plurálu CDLR, jimž jsou přiřazené názvy one a other.
Pluralizace není snadná — ale vyplatí se
Ano, pluralizace má spoustu hraničních případů, které nejsou snadno řešitelné. Mně ovšem v práci nesmírně pomohl MessageFormat ICU, poskytl mi nekonečnou flexibilitu při překladu řetězců do množného čísla. Jak se stále víc posouváme do propojenějšího světa, začíná být lokalizace aplikací do více jazyků samozřejmou nezbytností. Vnímat všeobecné lokalizační problémy a vědět o nástrojích, jimiž se dají řešit, to jsou znalosti, které už dnes prostě musíte mít. Aplikace potřebujeme lokalizovat proto, že svět je stále propojenější, měli bychom je ale lokalizovat také proto, abychom my sami pomáhali činit svět propojenějším.
O autorovi
Tingan Ho je designér, kodér a myslitel ze Švédska. Miluje web a všechna inovativní open-source řešení, která se webu týkají. Píše knihovny a nástroje, aby mohl svou každodenní práci s webovými technologiemi vykonávat efektivněji. Že má k webu co říct, si můžete zjistit na @tingan87.
[1] Pozn. př. Správně je króliki. Problém je daleko složitější, než si autor představuje. Množné číslo by se mělo řešit v součinnosti se skloňováním a rodem podstatných jmen. O duálu raději nemluvme. Pokud by chtěl autor vyřešit králičí problém v plné šíři, musel by se vypořádat se všemi možnými tvary singuláru a plurálu, aby mohl správně přeložit i dost jednoduché věty. V češtině například „O našich čtyřech králících“, „Jak Vám dupou králíci“, „Zastřelil jste tři králíky“ nebo „Spořádal půl králíka“. Připomínám, že v poslední větě nejde o tvar množného čísla pro zlomky, je to tvar pro druhý a čtvrtý pád jednotného čísla.
[2] Pozn. př. Uváděná pravidla pro polštinu a češtinu nejsou zdaleka úplná, protože všechna podstatná jména všech rodů se v polštině neskloňují podle vzoru miesiąc a v češtině ne podle vzoru den, což by mohl uživatel neznalý těchto jazyků z tamních tabulek usoudit. Ani ve francouzštině se množné číslo neřídí jen podle podstatného jména jour.
Článek byl přeložen se souhlasem Alistapart.com
Původní článek: Pluralization for JavaSript
- Translation: RNDr. Jan Pokorný
- Language and expert collaboration: Marek Machač







Mirek
Dub 17, 2015 v 8:16Velice zajímavý článek. Zatím jsem jej jen prolétl.
„Mnohé lokály nepotřebují úplně všechny tvary“: lokál je u mě hospoda, pivnice. Microsoft překládá locales jako „národní prostředí“ . Ale kodéři budou rozumět ;-)
jan
Kvě 15, 2015 v 12:34To malo byt vtipne?
jan semorad
Čvn 23, 2015 v 11:17bingo! super! díky!
jan semorad
Čvn 23, 2015 v 11:19skvělé! super! díky!
Jan Vítek
Pro 30, 2020 v 12:16Super článek. Zajímalo by mě, s jakým konkrétním číslem se použije polský tvar króliki. Podle seznamu se použije, pokud čítač má jakoukoliv jinou hodnotu, ale dle toho seznamu už žádnou jinou hodnotu mít nemůže, takže tvar króliki se nepoužije s žádným číslem ..
Taco
Pro 31, 2021 v 17:23Je to článek z roku 2015, a vývoj se nezastavil. Osobně považuji za aktuální špičku https://projectfluent.org/ (včetně podpory pro js https://github.com/projectfluent/fluent.js)