
Obsah
Související




Problém synchronizace dat v databázi Microsoft SQL Server se v praxi řeší poměrně často. Je několik způsobů, jak se s tím poprat. V tomto článku se podíváme na pokročilou synchronizaci dat pomocí DbMouse.
Synchronizace pomocí SQL scriptů
Nejpřímočařejším, ale také nejpracnějším řešením, je ručně si napsat SQL skripty pro synchronizaci. Předpokládejme, že chceme synchronizovat tabulku Source (sloupce ID, Value), do tabulky Target (sloupce ID, Value).
Pokud budou primární klíče shodné, a v tabulce Target není nastavena identita, dá se synchronizace provést skriptem:
-- insert
INSERT INTO Target (ID, Value)
SELECT ID, Value FROM Source
WHERE NOT EXISTS (SELECT * FROM Target WHERE Target.ID = Source.ID);
-- update
UPDATE Target
SET Value = Source.Value
FROM Target INNER JOIN Source ON Target.ID = Source.ID
-- delete
DELETE FROM Target
WHERE NOT EXISTS (SELECT * FROM Source WHERE Target.ID = Source.ID)
Tato metoda má své výhody:
- Nepotřebujete žádný nástroj, SQL skript si napíšete a pustíte kdekoliv
- Pokud jsou tabulky správně oindexovány, je to poměrně rychlé (v tomto jednoduchém případě pravděpodobně žádné indexy potřeba nebudou, na primárním kliči je index automaticky)
- SQL skript se dá uložit do stored procedury, případně pouštět pravidelně jako job na SQL serveru
A samozřejmě i nevýhody:
- Vytvořit takovýto SQL skript je poměrně pracné (pro každou tabulky jsou potřeba většinou 3 skripty, INSERT, UPDATE, DELETE)
- Lze synchronizovat pouze data, která jsou dostupná SQL dotazy (tj. nelze např. napojit CSV nebo XML soubory)
Synchronizace pomocí aplikací
Existuje spousta aplikací, které řeší synchronizaci dat, je možné např. napojit externí datové zdroje (CSV, XML soubory), synchronizovat data mezi různými databázemi (např. MySQL a Oracle) atd. Tyto aplikace pak přímo vkládají/přepisují data. Příkladem je RedGate SQL Data Compare. Tímto způsobem nelze ovšem vygenerovat skript pro synchronizaci (přesněji, někdy jde, ale skript pracuje jen s konkrétními daty, takže nelze použít např. jako tělo stored procedury pro pravidelnou synchronizaci).
Synchronizace pomocí DbMouse / DbShell
Jednoduše řečeno, synchronizace DbMouse funguje tak, že se „nakliká“ trochu podobně jako v jiných aplikacích pro synchronizaci, ale výsledkem je SQL script, který synchronizaci provede. Případně jde synchronizace uložit rovnou do stored procedury. Kromě toho tato metoda umožňuje pracovat s daty ve více propojených tabulkách (do skriptů se pak vygenerují příslušné (většinou) LEFT JOINy ), opět správným oindexováním se dá dosáhnout rychlého běhu i velmi složité synchronizace.
Na následujícím obrázku je vidět, jak může vypadat synchronizace ve skriptu uvedeném výše:
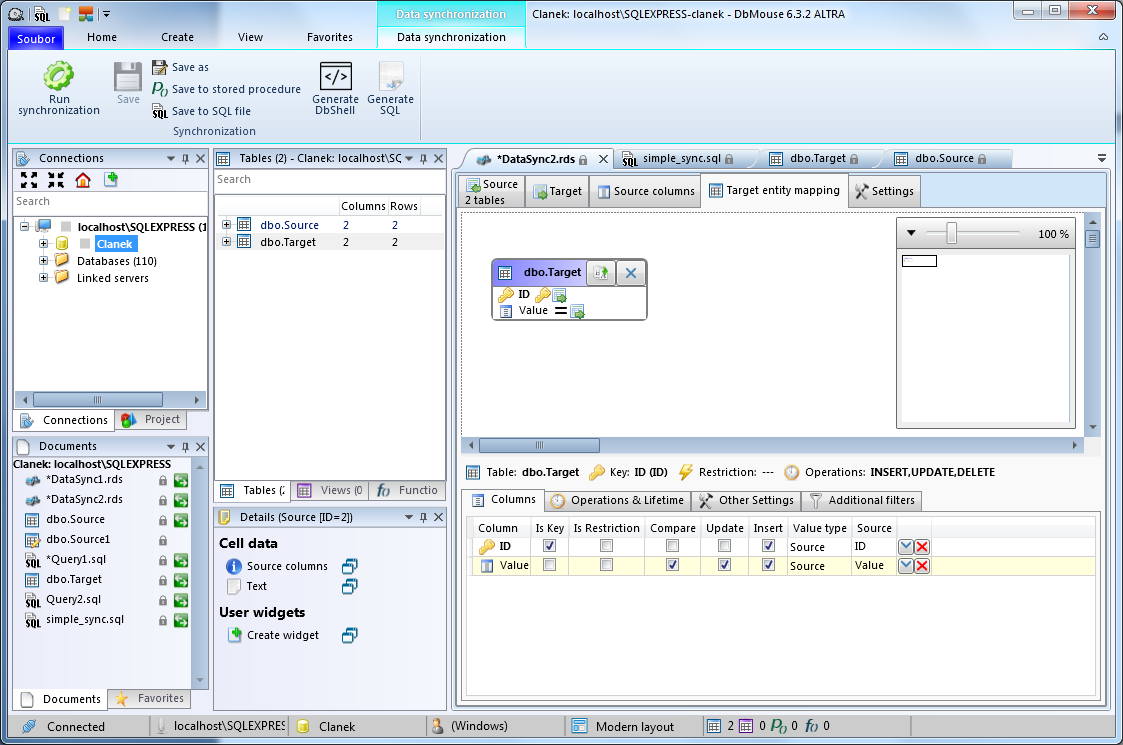
Když si odmyslíme výpisy logovacích hlášek a ošetření výjimek, vygenerovaný skript je v zásadě dost podobný skriptu ovedenému výše.
Za vysvětlení asi stojí sloupečky v tabulce „Columns“ ve spodní části definice synchronizace (v pořadí od nejjednodušších k těm komplikovanějším):
- Column – jméno sloupce v cílové tabulce
- Source – jméno sloupce ve zdrojové Umožňuje namapovat libovolně různě sloupce na sebe. Hodnota cílového sloupce se zkopíruje ze zdrojového sloupce.
- Is Key – zda je sloupec synchronizačním klíčem. Synchronizační klíč nemusí být (a většinou ani nebývá) klíčem primárním
- Value type – hodnota cílového sloupce nemusí být jen kopie dat ze zdroje, ale může to být i konstanta (např. pevný text nebo číslo), libovolný SQL výraz nebo různé speciální hodnoty (např. datum a čas importu)
- Compare, Update, Insert – zda se sloupec porovnává na změny se zdrojem / modifikuje dle zdroje / vkládají se do něj nové hodnoty
- Is Restriction – zda je sloupec omezující podmínkou. Tato funkce umožňuje omezit řádky v cílové tabulce, které budou ovlivněny importem. Např. pokud má tabulka sloupec „IsImported“, má smysl nastavit omezení na hodnotu 1, řádky s hodnotou IsImported=0 pak zůstanou po provedení importu netknuty.
Import dat do svázaných tabulek
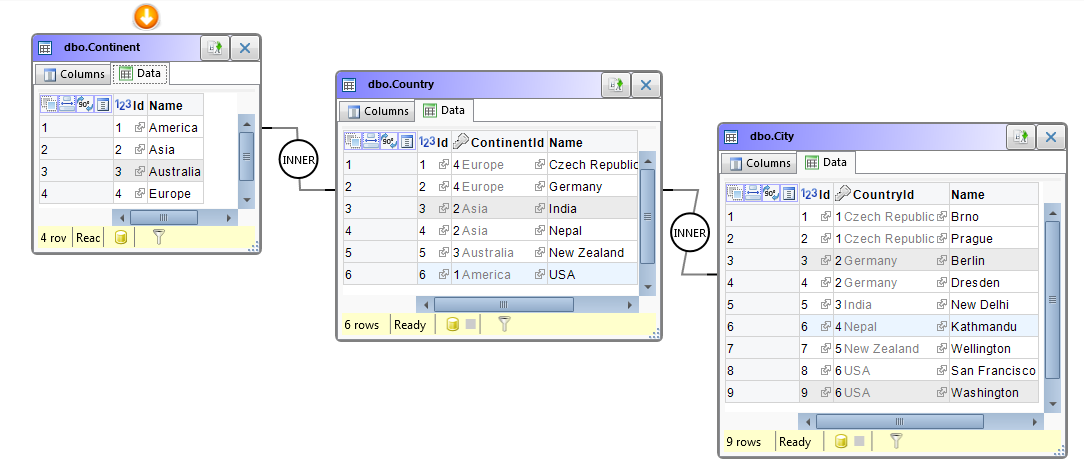
Ukážeme si trochu složitější situaci. Na vstupu máme jednu širokou tabulku (SourceData), úkolem je udělat synchronizaci do více svázaných tabulek (Continent, Country, City).
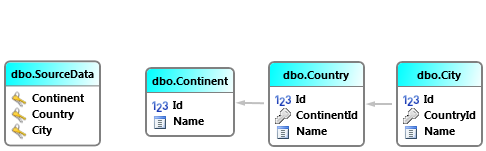
Data v tabulce SourceData můžou vypadat např. takto:
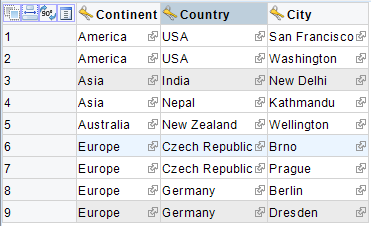
Tato situace je v praxi docela častá, vstupní data mohou být i v jiné databázi, popř. na linkovaném serveru. Stejně lze naimportovat i data třeba z Excelu.
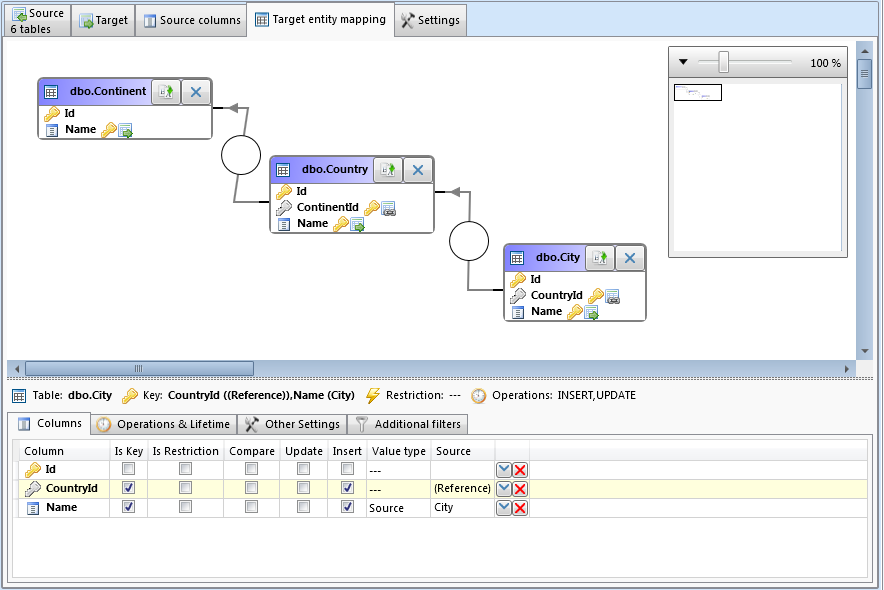
Na následujícím obrázku je mapování pro tuto synchronizaci. V seznamu sloupců dole jsou sloupce tabulky City, pro ostatní tabulky je to analogické.
- Sloupec Id není nijak namapovaný, jelikož se jedná o identitu (automaticky generovaný číselný primární klíč).
- Sloupec CountryId je definován jako reference na tabulku Country (tato reference se automaticky přednastaví z cizích klíčů, je možné ji nastavit i jinak).
- Sloupec Name se bere ze sloupce City ve zdrojové tabulce.
- Jako synchronizační klíč je nastavena dvojice (CountryId, Name). Synchronizační klíč je množina sloupců, jejichž hodnoty jednoznačně určují řádek ve zdrojové i v cílové tabulce. Tedy jako synchronizační klíč nelze použít primární klíč Id, protože ten není ve zdrojové tabulce. Pokud bychom použili pouze sloupec Name, v zásadě by to stačilo, pokud by jména měst byla jednoznačná. Pokud by existovala 2 města v různých zemích se stejným jménem, do tabulky City by se dostalo jen jedno.
Pro ilustraci přikládám vygenerovaný SQL skript (pouze pro INSERT, zjednodušený)
INSERT INTO [dbo].[City] ([Name], [CountryId])
SELECT [dbo.SourceData].[City], [dst_1].[Id]
FROM [dbo].[SourceData] [dbo.SourceData]
LEFT JOIN [dbo].[Continent] [dst_2] ON [dbo.SourceData].[Continent] =[dst_2].[Name]
LEFT JOIN [dbo].[Country] [dst_1] ON [dbo.SourceData].[Country] =[dst_1].[Name]
AND [dst_2].[Id]=[dst_1].[ContinentId]
WHERE ([dbo.SourceData].[City] IS NOT NULL AND [dst_1].[Id] IS NOT NULL AND NOT EXISTS
(SELECT * FROM [dbo].[City] [tested] WHERE ([tested].[Name] =[dbo.SourceData].[City]
AND [tested].[CountryId]=[dst_1].[Id])))
GROUP BY [dbo.SourceData].[City], [dst_1].[Id];
Vidíme, že ve svém důsledku je potřeba udělat LEFT JOIN i na tabulku Continent (protože v tabulce Country je sloupec ContinentId také součástí synchronizačního klíče, analogicky jako v tabulce City je to sloupec CountryId). Vygenerovaný skript zaručí, že jeden řádek ve svázaných tabulkách Continent, Country , City, bude odpovídat jednomu řádku ve zdrojové tabulce SourceData.
Na následujícím obrázku je vidět očekávaný výsledek, pokud synchronizaci pustíme:
Shrnutí
Cílem tohoto článku bylo ukázat možnosti synchronizace dat generováním SQL skriptu pomocí DbMouse v kontextu jiných metod synchronizace. Samozřejmě se se nevešlo všechno, trochu stranou jsme nechali definování zdrojových dat (zde to pro jednoduchost byla vždy jedna široká tabulka), a napojení na externí datové zdroje (např. zmíněný import z MS Excel).








